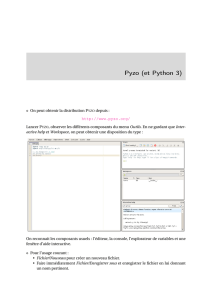
TP : commande awk
D'après le cours en ligne de Isabelle Vollant http://www.shellunix.com/awk.html
Nous reprenons dans ce TP une grande partie du cours de Isabelle Vollant en simplifiant quelques
informations.
Cette commande permet d'appliquer un certain nombre d'actions sur un fichier. La syntaxe est
inspirée du C.
Pour réaliser les exercices, vous récupérerez le répertoire de travail « fic_awk » composé de fichiers
de résultats à analyser.
Syntaxe
awk [-Fs] [-v variable] [-f fichier de commandes] 'program' fichier
-F Spécifie les séparateurs de champs
-v Définie une variable utilisée à l'intérieur du programme.
-f Les commandes sont lues à partir d'un fichier.
Principe de fonctionnement
Le programme awk est une suite d'actions de la forme : motif { action } , le motif permet de
déterminer sur quels enregistrements est appliquée l'action.
Un enregistrement est une chaîne de caractères séparée par un retour chariot, en général une
ligne.
Un champ est une chaîne de caractères séparée par un espace (ou par le caractère spécifié par
l'option -F), en général un mot.
On accède à chaque champ de l'enregistrement courant par la variable $1, $2, ... $NF. $0
correspond à l'enregistrement complet. La variable NF contient le nombre de champs de
l'enregistrement courant, la variable $NF correspond donc au dernier champ.
Donc la suite d'actions sera appliquée à tous les enregistrements qui vérifieront le motif. Lorsque
nous désirons faire une action une seule fois, alors on utilisera les variables BEGIN (quand on veut
que ce soit au début du programme) ou/et END (quand on veut que ce soit à la fin du programme).
Quelques variables prédéfinies
Variable Signification Valeur par défaut
ARGC Nombre d'arguments de la ligne de commande -
ARGV Tableau des arguments de la ligne de commande -
FNR Nombre d'enregistrements du fichier -
FILENAME Nom du fichier en entrée -
FS Séparateur de champs en entrée '' ''
NF Nombre de champs de l'enregistrement courant -
NR Nombre d'enregistrements déjà lus -
RS Séparateur d'enregistrements en entrée ''\n''

Quelques exemples très simples
Dans les exemples suivants il n'y a qu'un enchaînement de type motif { action } , et le seul motif
utilisé est dans le dernier exemple qui est le motif END. Donc dans les exemples toutes les actions
seront appliquées à tous les enregistrements du fichier en entrée
awk '{print $NF}' fichier : affiche le dernier champ de chaque ligne du fichier (quand il n'y a
pas de motif particulier, l'action est faite pour tous les enregistrements)
who | awk '{print $1,$3}' : affiche le login et la date de connexion
awk 'END {print NR}' fichier : affiche le nombre total de lignes du fichier (affiche en fait à la
fin le nombre total d'enregistrements lus une fois, et non pour chaque enregistrement)
awk -F ":" '{ $2 = "" ; print $0 }' /etc/passwd : affiche chaque ligne du fichier
/etc/passwd après avoir effacé le deuxième champ (mis le deuxième champ à vide)
Exercice 1
Vous testerez dans cet exercice quelques lignes de commande utilisant la commande awk, en
utilisant comme fichier d'entrée le fichier ''timings_SPIR_CUDA_2500_194.txt'' se trouvant dans
l'archive à récupérer sur le site de l'enseignant, répertoire que vous recopierez sur votre compte.
1. Ecrire une ligne de commande qui fait la même chose que le 3e exemple (afficher le nombre
de total de lignes du fichier) mais avec d'autres variables.
2. Quelle différence alors entre NR et FNR ? Pour voir cette différence refaites une commande
qui affiche les 2 valeurs ligne après ligne, en donnant 2 fichiers à lire et non 1. Prenez un
autre fichier dans le répertoire AWK.
3. Ecrire une ligne de commande qui affiche pour chaque ligne (ou enregistrement) son
numéro, son nombre de champs, et enfin la valeur de son dernier champ.
Syntaxe du motif
Si le motif existe dans l'enregistrement, l'action sera appliquée à la ligne.
Le motif peut être :
•une expression régulière simple ou composée comme ci-après :
•/exp reg/ où ''exp reg'' est une simple expression régulière et dès qu'une ligne
contient une telle expression on lui applique l'action qui suit
•$0 ~ /exp reg/ : la ligne est une expression régulière de la forme '' exp reg''
•expression ~ /exp reg/ : la ligne contient une ''expression'' qui est de la
forme '' exp reg''
•expression !~ /exp reg/ : la ligne contient une ''expression'' qui n'est pas de
la forme '' exp reg''
•une expression BEGIN ou END
•une expression de comparaison: <, <=, == , !=, >=, >
•une combinaison des trois (à l'aide des opérateurs booléens || ou, && et, ! négation)
•une caractérisation des lignes
motif1,motif2 : chaque ligne entre la première ligne correspondant au motif1 et la première
ligne correspondant au motif2
Exemples :
•Exemple 0
awk 'length($0)>75 {print}' fichier : affiche les lignes de plus de 75 caractères (chaque
enregistrement teste si sa ligne contient plus de 75 caractères et si oui alors exécute l'action qui est
d'afficher la ligne ($0)). ''print'' équivaut à ''print $0''.

•Exemple 1
awk 'BEGIN { print "Verification des UID et GID dans le fichier
/etc/passwd";
FS=":"}
$3 !~ /^[0-9][0-9]*$/ {print "UID erreur ligne "NR" :\n"$0 }
$4 !~ /^[0-9][0-9]*$/ {print "GID erreur ligne "NR" :\n"$0 }
END { print "Fin" }
' /etc/passwd
Résultat :
Verification des UID et GID dans le fichier /etc/passwd
UID erreur ligne 14 :
clown:*:aaa:b:utilisateur en erreur:/home/clown:/bin:sh
GID erreur ligne 14 :
clown:*:aaa:b:utilisateur en erreur:/home/clown:/bin/sh
Fin
•Exemple 2
awk 'BEGIN { print "Verification du fichier /etc/passwd pour ...";
print "- les utilisateurs avec UID = 0 " ;
print "- les utilisateurs avec UID >= 60000" ;
FS=":"}
$3 == 0 { print "UID 0 ligne "NR" :\n"$0 }
$3 >= 60000 { print "UID >= 60000 ligne "NR" :\n"$0 }
END { print "Fin" }
' /etc/passwd
Résultat :
Verification du fichier /etc/passwd pour ...
- les utilisateurs avec UID = 0
- les utilisateurs avec UID >= 60000
UID 0 ligne 5 :
root:*:0:b:administrateur:/:/bin/sh
UID >= 60000 ligne 14 :
clown:*:61000:b:utilisateur en erreur:/home/clown:/bin/sh
Fin
•Exemple 3
awk 'BEGIN { print "Verification du fichier /etc/group";
print "le groupe 20 s'appelle t-il bien users ? " ;
FS=":"}
$1 == "users" && $3 ==20 { print "groupe "$1" a le GID "$3" !" }
END { print "Fin" }
' /etc/group
Résultat :
Verification du fichier /etc/group
le groupe 20 s'appelle t-il bien users ?
groupe users a le GID 20 !
Fin
•Exemple 4
awk 'NR == 5 , NR == 10 {print NR" : " $0 }' fichier : affiche de la ligne 5
à la ligne 10 du fichier en entrée, chaque ligne précédée par son numéro

Exercice 2
Vous testerez, comme dans l'exercice 1, quelques lignes de commande utilisant la commande awk,
en utilisant comme fichier d'entrée le fichier ''timings_SPIR_CUDA_2500_194.txt''
1. Ecrire une commande qui permet d'afficher la dernière ligne du fichier.
2. Ecrire une ligne de commande qui permet d'afficher uniquement les lignes de la forme :
4.16user 2.30system 0:06.49elapsed 99%CPU (0avgtext+0avgdata 0maxresident)k
et qui met le numéro des lignes devant. Puis vous enrichirez la ligne de commande afin de compter
le nombre de lignes de cette même forme.
Exercice 3
Dans le fichier annuaire vous chercherez les lignes :
•qui ont un champ qui devrait contenir un numéro et qui contient autre chose : vous
afficherez alors un message en indiquant le nom du propriétaire et le n° de la ligne ;
•qui ont un numéro de portable qui n'en est pas un (qui commence par autre chose que 06),
vous afficherez alors un message ainsi que le nom du propriétaire et le numéro erroné ;
Vous pourrez écrire une seule ligne de commande en séparant les lignes par des '' ;'', ou écrire les
lignes de votre commande awk dans un script que vous nommez par exemple ''essai_awk'' et ensuite
vous pourrez lancer votre commande en tapant la ligne de commande suivante dans le terminal :
awk -f essai_awk
Les actions
Les actions permettent de transformer ou de manipuler les données, elles contiennent 1 ou plusieurs
instructions. Les actions peuvent être de différents types : fonctions prédéfinies, fonctions de
contrôle, fonctions d'affectation, fonctions d'affichage.
Les structures de contrôle
Présentation
Parmi les structures de contrôle, on distingue les décisions (if, else), les boucles (while, for, do-
while, loop) et les sauts (next, exit, continue, break).
Les décisions (if, else)
La syntaxe est la suivante:
if (condition)
instruction1
else
instruction2
Si vous avez une suite d'instructions à exécuter, vous devez les regrouper entre deux accolades.
Exemple:
awk ' BEGIN{print "test de l absence de mot de passe";FS=":"}
NF==7
{ #pour toutes les lignes contenant 7 champs
if ($2=="") # si le deuxième champ est vide (correspond au mot de passe crypté))
{ print $1 " n'a pas de mot de passe"} # on affiche le nom de l'utilisateur
($1=login) qui n'a pas de mot de passe
else
{ print $1 " a un mot de passe"} # on affiche le nom de l'utilisateur possédant un
mot de passe
}

END{print"C'est fini") ' /etc/passwd
Les boucles (while, for, do-while)
while, for et do-while sont issus du langage de programmation C.
1. while
La syntaxe de while est la suivante :
while (condition)
instruction
Exemple:
awk ' BEGIN{print"affichage de tous les champs de passwd";FS=":"}
{ i=1 # initialisation du compteur à 1 (on commence par le champ 1)
while(i<=NF) # tant qu'on n'est pas en fin de ligne
{ print $i # on affiche le champ
i++ # incrémentation du compteur pour passer d'un champ au suivant
}
}
END{print"C'est fini") ' /etc/passwd
Exercice 3bis :
Ecrire une commande qui permet d'afficher la dernière ligne du fichier d'une manière différente que
dans l'exercice 2.
Exercice 4 :
Dans un fichier vous rechercherez et afficherez, pour chaque ligne le premier champ dont la
longueur est égale à Max_Long. Si la ligne ne contient pas un tel champ alors affichez un message
d'erreur pour indiquer que cette ligne-ci (numéro de la ligne) n'a pas de champ de cette longueur.
La valeur de Max_Long sera modifiée en fonction des fichiers.
Exemples : vous prendrez 10 pour le fichier annuaire ; vous prendrez 8 pour timings... ; vous
prendrez histoire_sans_fin et vous chercherez le premier mot qui est de longueur 3.
Dans cet exercice vous pourrez écrire vos lignes de commande dans un fichier les appeler ensuite en
tapant la commande awk -f .…
Exemple :
dans votre fichier ''essai_awk'' vous mettez les lignes suivantes
BEGIN{print" affichage de tous les champs de passwd";FS=":"}
{
for (i=1;i<=NF;i++) # initialisation du compteur à 1, on incrémente le compteur jusqu'à ce qu'on
atteigne NF (fin de la ligne)
{ print $i } # on affiche le champ tant que la condition n'est pas satisfaite
}
END{print"C'est fini")
Puis vous appelez votre fichier awk de la manière suivante :
awk -f essai_awk /etc/passwd
Vous pouvez également mettre dans un fichier shell votre commande complète, et appelez ensuite
votre fichier comme un exécutable
Exemple :
dans votre fichier ''essai_awk.sh'' vous mettez les lignes suivantes
 6
7
8
6
7
8
1
/
8
100%