Structures phrastiques et analyse automatique des données

Structures phrastiques et analyse automatique des données
morphosyntaxiques : le projet LatSynt
LASLA –
LASLA –
Résumé
Abstract
Key-words:
0. Introduction
a priori

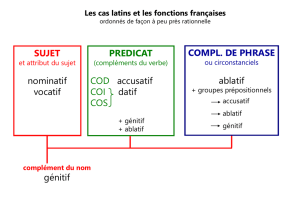
1. La banque de données et le système d’annotation du LASLA
Lexicon totius
latinitatis
ars citandi
1. Lemme 2. 3.Forme 4.Référence 5. Morpho. 6. Synt.
itinera
erant
erant
possent
qui

2. Le projet LatSynt
2.1. Sur le plan méthodologique et linguistique
LatSynt
2.2. Sur le plan des applications concrètes
3. La première phase du projet : un bornage des propositions
LatSynt
délimiter les propositions subordonnées
et de préciser leur niveau de subordination (c’est-à-dire d’enchâssement syntaxique)

cum
cum
cum
qui
quem
[…] uidi
quemuidi

Annales
Guerre des
GaulesAnnales
4. Les résultats obtenus et les perspectives de recherche
cumutubisi
eo
cum
ubi postquameo
cum
ubi
cum
 6
7
8
9
10
6
7
8
9
10
1
/
10
100%