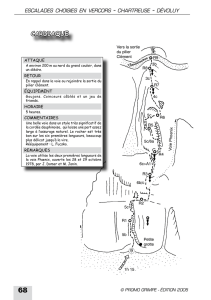
aléatoire probabilité -mesurée -partie -simulation alors

1
Terminologie statistique
Distribution de la moyenne: théorème central-limite
distribution Khi-deux (χ2)
distribution T de Student
distribution F de Fisher
résumé des distributions
Distributions d’échantillonnage
Bernard CLÉMENT, PhD MTH2302 Probabilités et méthodes statistiques
hors programme : distribution de S / distribution de R

2
Constats et terminologie statistique
•les populations statistiques sont modélisées par des distributions de
•probabilités dont les paramètres sont toujours inconnus;
•le mieux que l’on puisse faire: estimer les paramètres avec des
données échantillonnales (observations) provenant de la même distribution
(population);
•les données (Y1, Y2, …) sont transformées en statistique Wpar une fonction
W= h (Y1, Y2,…. ) W est une variable aléatoire
le choix de h dépend de l’application envisagée (ESTIMATION ou TEST)
la loi de probabilité de Ws’appelle distribution d’échantillonnage;
exemple : 2 échantillons de taille n provenant de la même population
(Y1, Y2, …, Yn) et (Y1’, Y2’, ….., Yn’) auront une moyenne (xbar),
différente, un écart type s différent, un histogramme différent :
c’est l’influence de la variabilité de l’échantillonnage;
Bernard CLÉMENT, PhD MTH2302 Probabilités et méthodes statistiques

3
Constats et terminologie statistique
•on dispose toujours que d’un seul échantillon de taille n
pour la mise en œuvre d’une procédure statistique:
ESTIMATION chapitre 10
TEST D’HYPOTHÈSES chapitre 11
•paramètre statistique ξ:
quantité associée à une distribution
exemples
ξ=μmoyenne distribution : exemple normale
ξ= σécart type distribution quelconque
ξ= θmoyenne distribution Bernoulli (θ)
ξ= θ(1- θ)variance distribution Bernoulli (θ)
ξ= xpp-ième percentile d’une variable X
Bernard CLÉMENT, PhD MTH2302 Probabilités et méthodes statistiques

4
Terminologie statistique
Échantillon aléatoire (définition)
un ensemble de variables aléatoires Y 1, Y 2, .., Y ntelles que
(a) les variables sont soumises à une même loi f(y)
(b) les variables sont indépendantes
loi conjointe : g (Y1, Y2, …, Yn) = f( Y1)* f(Y2) * …* f(Yn)
Statistique : toute fonction aléatoire établie sur l’échantillon
W = h (Y1, Y2, …., Yn)
remarque : W est une variable aléatoire
Estimateur : une statistique particulière conçue de façon à fournir
une estimation d’un paramètre d’une loi de probabilité
Aplications: Estimation
Test d’hypothèses
Régression
Analyse de la variance
Bernard CLÉMENT, PhD MTH2302 Probabilités et méthodes statistiques

5
Résultat 1 Soit Y 1, Y 2,, ….. , Y ndes v. a. indépendantes telles que
(rappel) E(Yi) = μiet Var (Yi)= σi2i = 1, 2, …, n
soient a 1,a 2,, …. , a ndes constantes et
i=n
soit W =∑ aiYiune combinaison linéaire des Yi
i=1
Alors E( W ) = μW= ∑ai μiet Var ( W ) = σw2= ∑ai2σi2
remarque 1 : aucune hypothèse est nécessaire sur les lois des Yi
remarque 2 : si les Yisont gaussiennes alors W est gaussienne
Résultat 3 Si les Yisont gaussiennes Yi~ N (μ, σ2)
alors Y est gaussienne N (μ, σ2/ n )
Résultat 2Soit ai= 1 / n E(Yi) = μVar( Yi) = σ2 alors
i=n
W = Y = Ybar = ∑ (1/n ) Yivérifie E(Y) = μet Var(Y) = σ2/ n
i=1
Bernard CLÉMENT, PhD MTH2302 Probabilités et méthodes statistiques
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
1
/
26
100%