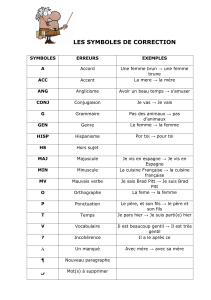
Mieux utiliser la base de données des programmes

Apéro Techno
Romain Maragou - Aliou Sow
Web sémantique

Plan :
Introduction
Cas d’utilisation chez Canal+
Mise en œuvre
Questions ?

Introduction
Utilise le web existant
Ensemble de technologies permettant de :
Structurer les informations
Les lier
Leur ajouter du sens (métadonnée)
Passer des pages Web à un index hiérarchisé
Favoriser la compréhension des données par des machines
Utiliser le langage naturel et avoir une réponse précise

Utilisation chez Canal+

Contexte d’utilisation chez Canal+
Base de données Programme
Canal+ achète de l’information (Plurimédia)
Informations du programme
Critiques, notes (Allociné)
Etc. …
Ajouter de l’information pertinente aux programmes
Recherche et recommandations plus précises et plus
pertinentes
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
1
/
30
100%