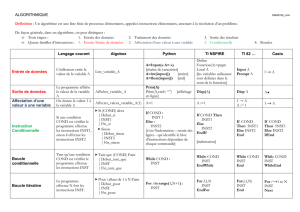
ppt, 315KB

Pipeline
Concept
Fonctionnement
Problèmes
BUS SYSTÈME
Registres
Unité de
traitement
Unité
flottante
Unité de
contrôle
Décodeur
PC
ALU
CPU
MÉMOIRE
PRINCIPALE DD IO IO
Cache
données
Cache
instructions MMU
TLB

Vue d'ensemble du processeur
RA
WA
RB
WEN
I0I1
Z
SHIFTER
R0 R1 R2 R3 R4 R5 R6 R7
SH2
SH1
SH0
AL2
AL1
AL0
OEN
SEL
Z≠0
1 0
INPORTOUTPORT
3
3
3
Mémoire
Séquenceur
CK
IR
Opcode Opérandes
Fanions
RAM
Contrôle
SLC
Opérandes
MDR MAR
CK
PC

Boucle de traitement
Décodage
Chargement
(opérandes)
Rangement
(opérandes)
Chargement
(instruction)
Exécution
L'instruction est cherchée en mémoire et chargée
dans le registre d'instruction (IR)
L'instruction est décodée pour en extraire les
signaux de contrôle pour l'unité de traitement
Les opérandes demandés par l'instruction sont
cherchés dans les registres ou en mémoire
L'opération demandée est effectuée sur les
opérandes choisis
Le résultat de l'opération est stocké dans un
registre ou en mémoire

IF ID OF EX OC
IF ID OF EX OC
IF ID OF EX OC
IF ID OF EX OC
Exécution - Timing
L'exécution d'une instruction comporte donc au plus 5 phases:
•le chargement de l'instruction (instruction fetch ou IF)
•le décodage de l'instruction (instruction decode ou ID)
•le chargement des opérandes (operand fetch ou OF)
•l'exécution de l'instruction (execute ou EX)
•le rangement des opérandes (operand commit ou OC)
Toutes les phases d'exécution n'ont pas la même durée.
INST 1
INST 2
INST 3
INST 4
CK
La fréquence maximale de l'horloge est déterminée par l'instruction
la plus lente (sans compter les cache miss).

Vue d'ensemble du processeur
SHIFTER
REGISTRES
I0
I1
Z
INPORT
Séquenceur
IR
Décodeur PC
Adresse Adresse INPORT OUTPORT
Chargement
(instruction)
Rangement
(opérandes)
Décodage Exécution
Chargement
(opérandes)
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
1
/
30
100%