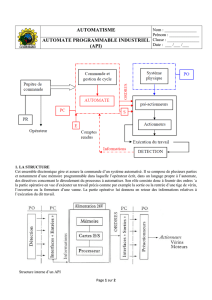
Langages formels, Calculabilité et Complexité

Langages formels,
Calculabilité et Complexité
Année 2007/2008
Formation interuniversitaire en informatique
de l’École Normale Supérieure
Olivier Carton
Version du 5 juin 2008

Rédaction
Une toute première version de ce support de cours a été rédigée pendant
l’année 2004/2005 par les élèves Gaëtan Bisson, François Garillot, Thierry Mar-
tinez et Sam Zoghaib. Ensuite, il a été complètement repris et très largement
étoffé par mes soins. Même si la version actuelle est relativement éloignée de la
première version, elle lui doit l’impulsion initiale sans laquelle elle n’existerait
peut-être pas. Certains passages ont aussi bénéficié de quelques travaux de ré-
daction des élèves. Malgré tous ces efforts, ce support de cours contient encore
de trop nombreuses erreurs et omissions. Une certaine indulgence est demandée
au lecteur. Les corrections et suggestions sont bien sûr les bienvenues.
Objectifs
Ce support de cours reflète les deux objectifs de ce cours. Le premier est d’ac-
quérir les principales notions élémentaires en langages formels, calculabilité et
complexité. Le second est de ne pas rester uniquement au niveau des définitions
et trivialités et de montrer quelques jolis résultats de ces différents domaines. Ce
choix fait que des résultats de difficultés très différentes se côtoient. Le premier
chapitre sur les langages rationnels contient par exemple le lemme de l’étoile
mais aussi la caractérisation de Schützenberger des langages sans étoile.
Plan
La structure de ce document reprend la division du cours en deux grandes
parties : les langages formels d’une part, calculabilité et complexité d’autre part.
Chacune de ces deux parties est scindée en deux chapitres. Les deux premiers
chapitres sont consacrés aux langages rationnels et aux langages algébriques et
les deux suivants à la calculabilité et à la complexité.
Téléchargement
Ce support de cours est disponible à l’URL
http://www.liafa.jussieu.fr/~carton/Enseignement/Complexite/ENS/Support/.

Table des matières
I Langages formels 7
1 Langages rationnels 9
1.1 Premières définitions . . . . . . . . . . . . . . . . . . . . . . . . . 9
1.2 Opérations rationnelles . . . . . . . . . . . . . . . . . . . . . . . . 11
1.3 Combinatoire des mots . . . . . . . . . . . . . . . . . . . . . . . . 12
1.3.1 Périodicités . . . . . . . . . . . . . . . . . . . . . . . . . . 12
1.3.2 Mots infinis . . . . . . . . . . . . . . . . . . . . . . . . . . 16
1.3.3 Motifs inévitables . . . . . . . . . . . . . . . . . . . . . . . 17
1.3.4 Codes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
1.4 Un peu d’ordre . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
1.4.1 Quasi-ordres sur les mots . . . . . . . . . . . . . . . . . . 25
1.4.2 Ordres sur les mots . . . . . . . . . . . . . . . . . . . . . . 26
1.4.3 Quasi-ordres sur les arbres . . . . . . . . . . . . . . . . . . 27
1.5 Langages rationnels . . . . . . . . . . . . . . . . . . . . . . . . . . 29
1.5.1 Expressions rationnelles . . . . . . . . . . . . . . . . . . . 29
1.5.2 Automates . . . . . . . . . . . . . . . . . . . . . . . . . . 31
1.6 Automates déterministes . . . . . . . . . . . . . . . . . . . . . . . 37
1.7 Automate minimal . . . . . . . . . . . . . . . . . . . . . . . . . . 40
1.7.1 Quotients . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
1.7.2 Congruence de Nerode . . . . . . . . . . . . . . . . . . . . 41
1.7.3 Calcul de l’automate minimal . . . . . . . . . . . . . . . . 43
1.8 Propriétés de clôture . . . . . . . . . . . . . . . . . . . . . . . . . 47
1.8.1 Opérations booléennes . . . . . . . . . . . . . . . . . . . . 47
1.8.2 Morphisme et morphisme inverse . . . . . . . . . . . . . . 47
1.9 Lemme de l’étoile et ses variantes . . . . . . . . . . . . . . . . . . 48
1.10 Hauteur d’étoile . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
1.11 Reconnaissance par morphisme . . . . . . . . . . . . . . . . . . . 53
1.12 Langages sans étoile . . . . . . . . . . . . . . . . . . . . . . . . . 60
1.13 Compléments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
1.13.1 Conjecture de Černý . . . . . . . . . . . . . . . . . . . . . 65
1.13.2 Rationnels d’un monoïde quelconque . . . . . . . . . . . . 66
2 Langages algébriques 69
2.1 Grammaires algébriques . . . . . . . . . . . . . . . . . . . . . . . 69
2.1.1 Définitions et exemples . . . . . . . . . . . . . . . . . . . 69
2.1.2 Grammaires réduites . . . . . . . . . . . . . . . . . . . . . 73
2.1.3 Grammaires propres . . . . . . . . . . . . . . . . . . . . . 74
2.1.4 Forme normale quadratique . . . . . . . . . . . . . . . . . 75
3

4TABLE DES MATIÈRES
2.2 Systèmes d’équations . . . . . . . . . . . . . . . . . . . . . . . . . 76
2.2.1 Substitutions . . . . . . . . . . . . . . . . . . . . . . . . . 77
2.2.2 Système d’équations associé à une grammaire . . . . . . . 77
2.2.3 Existence d’une solution pour S(G). . . . . . . . . . . . 78
2.2.4 Unicité des solutions propres . . . . . . . . . . . . . . . . 79
2.2.5 Théorème de Parikh . . . . . . . . . . . . . . . . . . . . . 80
2.2.6 Systèmes d’équations en commutatifs . . . . . . . . . . . 80
2.2.7 Solutions rationnelles des systèmes commutatifs . . . . . . 81
2.3 Arbres de dérivation . . . . . . . . . . . . . . . . . . . . . . . . . 83
2.3.1 Ambiguïté . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
2.3.2 Lemme d’itération . . . . . . . . . . . . . . . . . . . . . . 85
2.3.3 Applications du lemme d’itération . . . . . . . . . . . . . 87
2.3.4 Ambiguïté inhérente . . . . . . . . . . . . . . . . . . . . . 89
2.4 Propriétés de clôture . . . . . . . . . . . . . . . . . . . . . . . . . 89
2.4.1 Opérations rationnelles . . . . . . . . . . . . . . . . . . . 89
2.4.2 Substitution algébrique . . . . . . . . . . . . . . . . . . . 90
2.4.3 Intersection avec un rationnel . . . . . . . . . . . . . . . . 90
2.4.4 Morphisme inverse . . . . . . . . . . . . . . . . . . . . . . 91
2.4.5 Théorème de Chomsky-Schützenberger . . . . . . . . . . . 92
2.5 Forme normale de Greibach . . . . . . . . . . . . . . . . . . . . . 94
2.6 Automates à pile . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
2.6.1 Définitions et exemples . . . . . . . . . . . . . . . . . . . 96
2.6.2 Différents modes d’acceptation . . . . . . . . . . . . . . . 98
2.6.3 Équivalence avec les grammaires . . . . . . . . . . . . . . 100
2.6.4 Automates à pile déterministes . . . . . . . . . . . . . . . 102
2.7 Compléments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
2.7.1 Réécriture . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
2.7.2 Contenus de pile . . . . . . . . . . . . . . . . . . . . . . . 105
2.7.3 Groupe libre . . . . . . . . . . . . . . . . . . . . . . . . . 106
II Calculabilité et complexité 109
3 Calculabilité 111
3.1 Préliminaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
3.1.1 Graphes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
3.1.2 Logique propositionnelle . . . . . . . . . . . . . . . . . . . 113
3.2 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
3.2.1 Notion de problème . . . . . . . . . . . . . . . . . . . . . 113
3.2.2 Notion de codage . . . . . . . . . . . . . . . . . . . . . . . 114
3.2.3 Machines de Turing . . . . . . . . . . . . . . . . . . . . . 115
3.2.4 Graphe des configurations . . . . . . . . . . . . . . . . . . 119
3.2.5 Normalisation . . . . . . . . . . . . . . . . . . . . . . . . . 120
3.2.6 Variantes . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
3.3 Langages récursivement énumérables . . . . . . . . . . . . . . . . 129
3.4 Langages décidables . . . . . . . . . . . . . . . . . . . . . . . . . 131
3.5 Problème de correspondance de Post . . . . . . . . . . . . . . . . 136
3.5.1 Présentation . . . . . . . . . . . . . . . . . . . . . . . . . 136
3.5.2 Indécidabilité . . . . . . . . . . . . . . . . . . . . . . . . . 137
3.5.3 Application aux grammaires algébriques . . . . . . . . . . 139

TABLE DES MATIÈRES 5
3.6 Théorème de récursion . . . . . . . . . . . . . . . . . . . . . . . . 141
3.7 Machines linéairement bornées . . . . . . . . . . . . . . . . . . . 143
3.7.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
3.7.2 Grammaires contextuelles . . . . . . . . . . . . . . . . . . 144
3.7.3 Décidabilité . . . . . . . . . . . . . . . . . . . . . . . . . . 145
3.7.4 Complémentation . . . . . . . . . . . . . . . . . . . . . . . 146
3.8 Décidabilité de théories logiques . . . . . . . . . . . . . . . . . . . 149
3.8.1 Modèles et formules logiques . . . . . . . . . . . . . . . . 149
3.8.2 Arithmétique de Presburger . . . . . . . . . . . . . . . . . 150
3.9 Fonctions récursives . . . . . . . . . . . . . . . . . . . . . . . . . 153
3.9.1 Fonctions primitives récursives . . . . . . . . . . . . . . . 153
3.9.2 Fonctions récursives . . . . . . . . . . . . . . . . . . . . . 157
3.9.3 Équivalence avec les machines de Turing . . . . . . . . . . 157
3.9.4 Thèse de Church . . . . . . . . . . . . . . . . . . . . . . . 158
3.10 Compléments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 158
3.10.1 Écritures des entiers dans une base . . . . . . . . . . . . . 158
3.10.2 Machines de Turing sans écriture sur l’entrée . . . . . . . 161
4 Complexité 165
4.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 165
4.1.1 Objectifs . . . . . . . . . . . . . . . . . . . . . . . . . . . 165
4.1.2 Définition des complexités . . . . . . . . . . . . . . . . . . 165
4.2 Complexité en temps . . . . . . . . . . . . . . . . . . . . . . . . . 166
4.2.1 Théorème d’accélération . . . . . . . . . . . . . . . . . . . 166
4.2.2 Changements de modèles . . . . . . . . . . . . . . . . . . 167
4.2.3 Classes de complexité en temps . . . . . . . . . . . . . . . 168
4.2.4 NP-complétude . . . . . . . . . . . . . . . . . . . . . . . . 172
4.2.5 NP-complétude de Sat et 3Sat . . . . . . . . . . . . . . 173
4.2.6 Exemples de problèmes NP-complets . . . . . . . . . . . . 176
4.3 Complexité en espace . . . . . . . . . . . . . . . . . . . . . . . . . 183
4.3.1 Changement de modèle . . . . . . . . . . . . . . . . . . . 183
4.3.2 Classes de complexité en espace . . . . . . . . . . . . . . . 186
4.3.3 Complexités en temps et en espace . . . . . . . . . . . . . 186
4.3.4 Exemples de problèmes dans PSpace . . . . . . . . . . . 187
4.3.5 PSpace-complétude . . . . . . . . . . . . . . . . . . . . . 189
4.3.6 Espace logarithmique . . . . . . . . . . . . . . . . . . . . 190
4.3.7 NL-complétude . . . . . . . . . . . . . . . . . . . . . . . . 195
4.4 Théorèmes de hiérarchie . . . . . . . . . . . . . . . . . . . . . . . 197
4.5 Machines alternantes . . . . . . . . . . . . . . . . . . . . . . . . . 198
4.5.1 Définitions et exemples . . . . . . . . . . . . . . . . . . . 198
4.5.2 Complémentation . . . . . . . . . . . . . . . . . . . . . . . 200
4.5.3 Automates alternants . . . . . . . . . . . . . . . . . . . . 202
4.5.4 Classes de complexité . . . . . . . . . . . . . . . . . . . . 204
4.6 Compléments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 206
4.6.1 Machines à une bande en temps o(nlog n). . . . . . . . . 206
Bibliographie 214
Index 215
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
1
/
217
100%