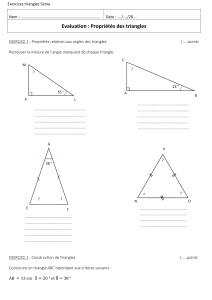
Accélération matérielle pour le rendu de scènes - Pastel

Acc´el´eration mat´erielle pour le rendu de sc`enes
multim´edia vid´eo et 3D
Christophe Cunat
To cite this version:
Christophe Cunat. Acc´el´eration mat´erielle pour le rendu de sc`enes multim´edia vid´eo et 3D.
Micro et nanotechnologies/Micro´electronique. T´el´ecom ParisTech, 2004. Fran¸cais. <tel-
00077593>
HAL Id: tel-00077593
https://pastel.archives-ouvertes.fr/tel-00077593
Submitted on 31 May 2006
HAL is a multi-disciplinary open access
archive for the deposit and dissemination of sci-
entific research documents, whether they are pub-
lished or not. The documents may come from
teaching and research institutions in France or
abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est
destin´ee au d´epˆot et `a la diffusion de documents
scientifiques de niveau recherche, publi´es ou non,
´emanant des ´etablissements d’enseignement et de
recherche fran¸cais ou ´etrangers, des laboratoires
publics ou priv´es.

Th`ese
pr´esent´ee pour obtenir le grade de docteur
de l’´
Ecole Nationale Sup´erieure
des T´el´ecommunications
Sp´ecialit´e : ´
Electronique et Communications
Christophe Cunat
Acc´el´eration mat´erielle pour le rendu
de sc`enes multim´edia vid´eo et 3D
Soutenue le 8 octobre 2004
devant le jury compos´e de
MM. Jean-Didier Legat : Pr´esident
Emmanuel Boutillon : Rapporteur
Habib Mehrez :
Franck Mamalet : Examinateur
Jean Gobert : Directeur de th`ese
Yves Mathieu :


Remerciements
Je tiens tout d’abord `a remercier les diff´erentes personnalit´es qui m’ont fait l’hon-
neur de participer `a mon jury de th`ese : M. Jean-Didier Legat qui m’a ´egalement fait la
faveur de pr´esider ce jury, MM. Emmanuel Boutillon et Habib Mehrez qui ont accept´e
la tˆache d’ˆetre les rapporteurs de ma th`ese ainsi que MM. Jean Gobert, Franck Mamalet
et Yves Mathieu.
Je tiens plus particuli`erement `a exprimer ma gratitude envers M. Yves Mathieu qui
a eu la lourde tˆache d’ˆetre mon directeur de th`ese. Ce travail n’aurait jamais abouti sans
son ind´efectible dynamisme et in´ebranlable conviction dans l’int´erˆet de mes travaux. Ses
constants encouragements m’ont toujours permis de d´epasser les diff´erentes p´eriodes de
d´ecouragement qui ont pu jalonner ces ann´ees de th`ese. Merci.
Je tiens ´egalement `a remercier la soci´et´e Philips France pour le cadre g´en´eral de
cette th`ese CIFRE avec, en particulier, MM. Joseph Ad´ela¨ıde, Marc Duranton et Jean
Gobert qui ont particip´e `a l’encadrement de mon travail. Qu’ils trouvent ici l’expression
de ma reconnaissance. Je remercie ´egalement M. Thierry Brouste pour m’avoir accueilli
au sein de son d´epartement tant au LEP, `a PRF qu’au PDSL-Paris.
Je n’oublie pas les personnes qui m’ont cˆotoy´e au quotidien dans ces d´epartements
et qui m’ont toujours exprim´e leur confiance dans la qualit´e de mon travail : Selim,
Ana, Boriana, Robin, Carolina, Thomas, Qin, Laurent, Olivier, Lien, Philippe. . . Je
pense aussi `a tous les membres du d´epartement Com´
Elec et aux nombreuses discussions
qui ont ´emaill´e nos repas et pause-caf´es : Jean, Jean-Claude, Jean-Luc, Sylvain, Lirida,
Renaud, Alexis, les deux Philippe, Cyril, Elizabeth. . . Je remercie ´egalement pour leur
disponibilit´e et leur gentillesse les agents administratifs de ces services : Chantal, Marie-
Dominique, Danielle et Marie. Je lui sais gr´e, ainsi qu’`a Jo¨elle, de m’avoir encourag´e
tout au long de ma formation initiale et de cette th`ese.
Je me permets de continuer cette ´enum´eration par les nombreux amis qui doivent
d´esormais pousser un soupir de soulagement : je ne leur rabattrai plus les oreilles avec
mes doutes existentiels. Je les remercie d’avoir pu me permettre de prendre suffisam-
ment de recul par rapport `a mon travail : Ovarith, Philippe, Baptiste, William, Ti-
moth´ee, Charles, Emmanuelle, Yannick, Fabien, Franck, Thierry, Nicolas, Laurent, Marc,
´
Edouard. Merci `a G´erard, Nicolas, Mouhcine et Fr´ed´eric pour nos pauses Chez ´
Eric. Sans
oublier Besan¸con : Christophe, Sandrine, St´ephane, Sylvain, S´ebastien, Aude. . .
Merci `a Pratchett et ses Annales du Disque-monde de me faire toujours rire.
Enfin, je terminerai en exprimant les sentiments que j’´eprouve envers mes parents
qui m’ont encourag´e durant toute ma vie d’´el`eve puis d’´etudiant. Je remercie ´egalement
mon fr`ere pour son soutien permanent. `
A tous, merci.

 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
1
/
249
100%