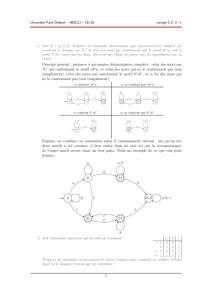
On repère assez facilement que les symboles A et C sont sans

Université Paris Diderot – HE01LI – 15/16 corrigé C.C. n◦2 & examen
1. Soit la grammaire Gsuivante : S−→ aS |cB |a
A−→ AS |CS
B−→ ε|bD
C−→ AB |AA
D−→ dD |S
(a) Proposer une nouvelle grammaire G′engendrant le même langage mais ne comprenant
pas de symboles inutiles.
On repère assez facilement que les symboles Aet C
sont sans contribution, et par conséquent inutiles. Ils
sont par ailleurs tous les deux inaccessibles. Les autres
symboles ont une contribution, et sont de plus acces-
sibles à partir de l’axiome.
La grammaire résultante est donnée ci-contre.
S−→ aS |cB |a
B−→ ε|bD
D−→ dD |S
(b) Est-ce que la grammaire G′est régulière ? Sinon, proposez une grammaire G′′ régulière
et engendrant le même langage.
Une grammaire régulière (gauche) ne contient que des
règles de la forme A→xB ou A→y. On tolère fré-
quemment en plus les ε-productions, ce que nous allons
faire dans ce corrigé. Il y a donc une seule règle fau-
tive, la règle D→S. Pour transformer cette règle, on
remplace Spar ses parties droites puisqu’elles sont ré-
gulières. La grammaire résultante est donnée ci-contre.
S−→ aS |cB |a
B−→ ε|bD
D−→ dD |aS |cB |a
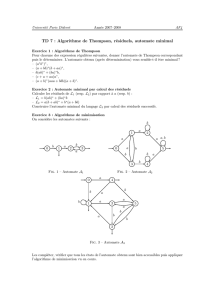
(c) Proposez un automate Aéquivalent à G′′ .
On applique l’algorithme de correspondance
grammaire-automate, les états correspondent
donc à des non-terminaux, la règle S−→ a
oblige à créer un état supplémentaire :
S B
X D
a
d
c
b
a
a c
a
(d) Proposez un automate A′minimal reconnaissant le même langage que A.
Pour chercher un automate minimal, il faut partir
d’une version déterministe et complète. Ici, l’algo-
rithme de déterminisation et la complétion abou-
tissent à l’automate suivant (on renomme Y l’état
composite X-S et on nomme Z l’état puits ajouté).
a b c d
→S Y Z B Z
←Y Y Z B Z
←B Z D Z Z
D Y Z B D
Z Z Z Z Z
L’algorithme de minimisation démarre avec deux classes distinctes {S, D, Z} et
{Y, B} (sur la base de la différence entre état final et état non final). La première
passe conduit à séparer Z de S et de D, et Y de B, ce qui donne le découpage
{S, D}, {Z}, {Y} et {B}. Enfin, l’étape suivante sépare S et D, ce qui mène à la
conclusion que l’automate est minimal.
1

Université Paris Diderot – HE01LI – 15/16 corrigé C.C. n◦2 & examen
(e) Proposez une grammaire régulière G′′′ engendrant le même langage.
On demandait implicitement de repartir du
dernier automate pour proposer une nouvelle
grammaire régulière. Si on applique mécani-
quement la méthode habituelle, on obtient la
grammaire donnée à droite.
S−→ aY |bZ |cB |dZ
Y−→ aY |bZ |cB |dZ |ε
B−→ aZ |bD |cZ |dZ |ε
D−→ aY |bZ |cB |dD
Z−→ aZ |bZ |cZ |dZ
Il est facile de constater que le non terminal
Z n’a pas de contribution, il est donc naturel
de proposer la grammaire équivalente donnée
ici, dans laquelle on a supprimé toutes les oc-
currences de Z.
S−→ aY |cB
Y−→ aY |cB |ε
B−→ bD |ε
D−→ aY |cB |dD
2. Soit l’automate suivant
1
2
3
4
0
aa
b
b
b
ba
a
a,b
(a) Quel est le langage reconnu par cet automate ? Décrivez ce langage en une phrase, et
proposez une expression rationnelle.
Les mots de ce langage comprennent un nombre pair de a(y compris 0), suivis
par un nombre impair de b. Ou encore : les mots de ce langage comprennent
un b, précédé d’un nombre pair de aet suivi d’un nombre pair de b. On peut
proposer l’expression rationnelle (aa)∗b(bb)∗.
(b) Appliquez l’algorithme de McNaughton & Yamada pour produire une expression ration-
nelle équivalente à l’automate.
On représente l’automate généralisé construit à partir de l’automate initial dans
la table suivante (chaque case représente la transition d’un état ià un état j,
par convention les lignes correspondent aux états de départ et les colonnes aux
états d’arrivée).
Il n’est pas utile d’inclure l’état 0 dans l’automate généralisé, car c’est un puits,
il n’y a donc aucun chemin (autre que ∅) partant de cet état. Mais ce n’était pas
interdit non plus, cela produit une (longue) étape de calcul qui ne change rien
aux colonnes restantes :
0 1 2 3 4 F
0a|b∅ ∅ ∅ ∅ ∅
I∅ε∅ ∅ ∅ ∅
1∅ ∅ a b ∅ ∅
2b a ∅ ∅ ∅ ∅
3a∅ ∅ ∅ b ε
4a∅ ∅ b∅ ∅
Suppression de 0 −→ 1 2 3 4 F
Iε∅ ∅ ∅ ∅
1∅a b ∅ ∅
2a∅ ∅ ∅ ∅
3∅ ∅ ∅ b ε
4∅ ∅ b∅ ∅
2

Université Paris Diderot – HE01LI – 15/16 corrigé C.C. n◦2 & examen
Les 4 étapes de suppression peuvent se faire dans n’importe quel ordre, les
expressions obtenues seront différentes mais équivalentes. Ici, on supprime dans
l’ordre 1, 2, 3, 4 :
1 2 3 4 F
Iε∅ ∅ ∅ ∅
1∅a b ∅ ∅
2a∅ ∅ ∅ ∅
3∅ ∅ ∅ b ε
4∅ ∅ b∅ ∅
2 3 4 F
Ia b ∅ ∅
2aa ab ∅ ∅
3∅ ∅ b ε
4∅b∅ ∅
3 4 F
I(a(aa)∗ab)|b∅ ∅
3∅b ε
4b∅ ∅
4 F
I((a(aa)∗ab)|b)b(a(aa)∗ab)|b
4bb b
F
I(((a(aa)∗ab)|b)b(bb)∗b)|((a(aa)∗ab)|b)
Avec un peu de chance ou d’intuition, on pouvait aussi procéder aux suppressions
dans l’ordre 2, 1, 4, 3, ce qui aboutit à l’expression (aa)∗b(bb)∗, ce qui est assez
rassurant.
3. Donner dans le pseudo-langage de votre choix un algorithme qui étant donné un automate
non déterministe et un mot ucompte le nombre de chemins dans l’automate qui permettent
de reconnaître le mot.
[Bonus] : proposer une variante qui donne la liste des chemins (c’est-à-dire des suites
d’états) qui permettent de reconnaître le mot. L’utilisation d’une pile est fortement
conseillée.
Une des méthodes les plus simples consistait à reprendre l’algorithme récursif de
parcours d’un automate non déterministe, en remplaçant le return qui se déclen-
chait en cas de parcours réussi par un compteur (variable globale), et en faisant en
sorte que le parcours soit complet. À gauche une version courante de l’algorithme
récursif, à droite la version répondant à la question.
def reco_ndet(a, s, u):
if u == "":
return final(a,s)
else:
for q in delta_ndet(a,s,u[0]):
if reco_ndet(a,q,u[1:]):
return True
return False
n = 0
def reco_ndet(a, s, u):
if u == "":
if final(a,s):
n+=1
else:
for q in delta_ndet(a,s,u[0]):
reco_ndet(a,q,u[1:])
Le bonus n’est pas corrigé.
3
1
/
3
100%




![Exercice 1 [Bac Liban 2016] : Solution page 1 Un automate peut se](http://s1.studylibfr.com/store/data/001876471_1-aac3bd8ca65b5f5251c8e166c1447a0c-300x300.png)