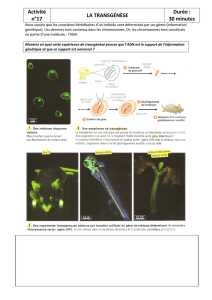
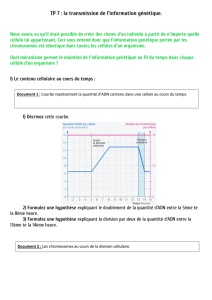
2 IFSI UE2.2S1 – Année 2012-2013 – Génétique Bourgeois

Texte du cours de Génétique – Dr Patrice Bourgeois & Pr Nicole Philip
1
IFSI UE2.2S1
– Année 2012-2013 – Génétique Bourgeois
IFSI première année
UE 2.2 S1 - Génétique
Texte du cours destiné à expliquer le diaporama
Avertissement
Certains concepts de ce cours ont été grandement simplifiés pour répondre
- À la très grande hétérogénéité des étudiants de première année d’IFSI
- À l’absence totale de connaissances biologiques et chimiques de base pour bon nombre
d’entre eux
- Le diaporama est prévu pour durer 8h et est divisé en quatre chapitres découpés selon le
référentiel ministériel, correspondant approximativement chacun à 2h (plutôt 1h pour le
chapitre 3 et 3h pour le chapitre 4)
Les concepts abordés sont
Dans le cours 1.
L’ADN, sa structure en simple puis en double brin, et son environnement dans la cellule
Le patrimoine génétique humain
Dans le cours 2.
Le cycle cellulaire et la conservation « horizontale » du patrimoine génétique
Le dogme central de la biologie moléculaire : transcription/maturation/traduction
La structure d’un gène eucaryote
Dans le cours 3.
La transmission « verticale » du patrimoine génétique
La méiose et le brassage génétique
Dans le cours 4.
Bases de génétique formelle et moléculaire
Modes de transmission d’allèles morbides les plus courants
Il est vivement conseillé aux étudiants et à leurs formateurs de se baser également sur le
référentiel de cours établi, qui synthétise les savoirs et les savoir-faire attendus des
étudiants à la fin de ce cours.
Mode d’emploi : ce déroulé de cours est complémentaire du pdf de cours et s’appuie sur les
illustrations contenues dans celui-ci. Les références entre guillemets dans le texte sont les titres des
diapositives correspondantes.

Texte du cours de Génétique – Dr Patrice Bourgeois & Pr Nicole Philip
2
IFSI UE2.2S1
– Année 2012-2013 – Génétique Bourgeois
Cours 1. Bases moléculaires de l’organisation du génome
Un organisme vivant est constitué de systèmes (système digestif, système reproducteur, système
nerveux….), qui remplissent chacun une fonction de base (digestion, reproduction, transmission
d’influx nerveux respectivement). Leur étude est la physiologie ou l’anatomie.
Un système comporte lui-même plusieurs organes, remplissant chacun une fonction distincte. Dans
le système digestif par exemple, l’estomac digère les aliments mécaniquement et chimiquement,
l’œsophage conduit les aliments de la bouche à l’estomac, le foie stocke régule la quantité de glucose
dans le sang et filtre les toxines.
Un organe est composé de différents tissus, eux-mêmes couches de cellules plus ou moins
complexes. L’étude des tissus est l’histologie. L’étude des cellules est la biologie cellulaire.
Une cellule est un assemblage complexe de molécules organiques et inorganiques. Les molécules
sont elles-mêmes des constructions groupant entre 2 et plusieurs milliers d’atomes. L’étude des
molécules biologiques dans la cellule est la biologie moléculaire, l’étude des réactions chimiques
dans la cellule (métabolisme) est la biochimie, l’étude des atomes et des molécules hors contexte
vivant est la chimie ou la physique.
Notre cours est à la frontière entre la biologie cellulaire, la biologie moléculaire et la biochimie.
Nous n’étudierons que 2 catégories de macromolécules biologiques dans ce cours, l’ADN et les
protéines.
Il est apparu très tôt, dès après la découverte de l’ADN en 1953, qu’un intermédiaire devait exister
entre l’information portée par la double hélice dans le noyau et les unités de fabrication des
protéines dans le cytoplasme.
C’est François Jacob et Jacques Monod qui ont découvert en 1963 la molécule de passage, qu’ils ont
baptisée ARN messager.
Les protéines sont des enchainements ordonnés d’unités de base qui sont les acides aminés. La
longueur de la chaîne et la composition en acides aminés font la spécificité de la protéine.
La séquence en acides aminés d’une protéine est directement spécifiée par le gène qui la code.
Cette séquence détermine la forme de la protéine, donc sa fonction.
Les 20 acides aminés ont la même structure de base autour d’un carbone asymétrique (alpha), avec
un groupe amine -NH2, un groupe acide carboxylique -COOH et une chaîne latérale qui varie. Les 2
groupes fonctionnels sont ionisés en solution, les acides aminés sont donc des composés amphotères
(ayant une double propriété acide et basique).
Sur ces 20 acides aminés, nous sommes capables par le métabolisme d’en fabriquer 12. Il existe donc
8 acides aminés que nous ne savons pas synthétiser, ils sont dits essentiels, et doivent être apportés
par l’alimentation.
Il existe encore d’autres acides aminés, mais dont l’utilisation est beaucoup plus rare (par exemple, la
séléno-cystéine).
Structure moléculaire en double hélice de la molécule d’ADN.
L’ADN est un enchaînement ordonné d’unités de base qui sont les nucléotides.
Il existe 4 nucléotides différents A, T, G et C.
L’enchainement des nucléotides est appelé la séquence.
La structure en double hélice lui confère une propriété d’auto-réplication qui assure la conservation
de l’information génétique (intégrité, stabilité).
C’est la séquence des nucléotides qui porte l’information génétique. L’ordre des nucléotides est
signifiant.

Texte du cours de Génétique – Dr Patrice Bourgeois & Pr Nicole Philip
3
IFSI UE2.2S1
– Année 2012-2013 – Génétique Bourgeois
L’image présentée en début de ce chapitre est une vue de l’esprit. En réalité dans la cellule, l’ADN
n’est jamais sous cette forme nue. Il est toujours couvert de protéines.
On considère que l’ensemble de l’ADN contenu dans la cellule conditionne la forme et le
fonctionnement de la cellule, donc de l’organisme.
Hormis l’ADN trouvé dans le noyau (ADN nucléaire, majoritaire), il existe un petit ADN circulaire
trouvé dans les mitochondries, l’ADN mitochondrial. Des mutations de cet ADN sont également
responsables de maladies génétiques sévères (pathologies mitochondriales, de découverte
relativement récente, c’est un domaine en plein essor).
Les unités de bases de l’ADN sont elles-mêmes un assemblage de 3 plus petites molécules toujours
associées selon le même mode. Un groupement phosphate PO3--, est relié par une liaison covalente
à un sucre, de la famille des aldopentoses (5 atomes de carbone), le désoxyribose. Ce sucre porte
une base azotée, et c’est la base azotée qui diffère selon le nucléotide. Il existe 4 types de bases
azotées, l’Adénine, la Guanine, la Cytosine et la Thymine. A et G sont des purines, C et T sont des
pyrimidines.
Le nucléotide qui porte la base Adénine s’appelle désoxyAdénosine
Le nucléotide qui porte la base Guanine s’appelle désoxyGuanosine
Le nucléotide qui porte la base Cytosine s’appelle désoxyCytidine
Le nucléotide qui porte la base Thymine s’appelle désoxyThymidine
Par abus de langage, on confond souvent le nucléotide avec la base azotée qu’il comporte, et on
appelle indifféremment A, G, C ou T la base seule ou le nucléotide correspondant.
Le sucre d’un nucléotide peut se lier par une liaison covalente au groupement phosphate du
nucléotide suivant (liaison phosphodiester), dont le sucre peut lui-même se lier au phosphate d’un 3e
nucléotide, et ainsi de suite. On comprend donc qu’il se créée une orientation dans la chaîne.
Finalement, on constitue un enchaînement orienté de phosphates et de sucres alternés qui forment
un brin d’ADN. Les bases azotées de ces nucléotides pointent perpendiculairement à cet axe
sucre/phosphate.
On « lit » la séquence de ce brin d’ADN en déterminant l’ordre des bases azotées portées par les
nucléotides successifs dans le sens de progression.
Ainsi dans l’exemple donné en cours, la séquence du brin représenté est TGCA.
Cette séquence est spécifique, elle est différente de ACGT ou de AGCT ou de toutes les autres
combinaisons possibles.
Ici encore, on confond volontiers le nucléotide et la base qu’il porte (puisque de toutes façons, le
sucre et le phosphate sont toujours les mêmes), donc quand on écrit TGCA, cela peut vouloir dire
qu’on parle des 4 nucléotides, ou des 4 bases.
La découverte de la structure de l’ADN est relativement récente dans l’histoire des sciences.
Elle a été rendue possible du fait de la structure régulière de la double hélice, qui peut cristalliser.
Watson et Crick sont des physiciens, Wilkins et Franklin des chimistes. Ce ne sont pas des biologistes
qui ont réalisé cette découverte !
Pourtant, c’est toute la biologie moléculaire qui a démarré à partir de ce moment fondamental dans
l’histoire des sciences, permettant l’essor des biotechnologies, de la génétique, et de toutes les
avancées d’aujourd’hui.
Seuls Watson, Crick et Wilkins ont eu le prix Nobel pour cette découverte (alors que c’est Franklin qui
a réalisé les clichés de diffraction et analysé les images obtenues), pour la double raison que c’était
une femme (on a volontairement tenté de diminuer son rôle dans l’histoire), mais surtout qu’elle est
décédée peu de temps avant la remise des prix, et le Nobel ne peut être décerné à titre posthume.

Texte du cours de Génétique – Dr Patrice Bourgeois & Pr Nicole Philip
4
IFSI UE2.2S1
– Année 2012-2013 – Génétique Bourgeois
On trouve de l’ADN dans les momies, dans certaines fossiles, dans les insectes conservés dans
l’ambre, dans les animaux congelés sous la banquise… cette résistance exceptionnelle est due en
partie à la structure particulière de la molécule d’ADN.
C’est un assemblage de 2 brins d’ADN l’un en face de l’autre, en orientation inverse.
En face de chaque nucléotide, vient se placer un autre nucléotide qui s’associe avec lui.
On mesure ainsi les « distances » sur la molécule d’ADN en nombre de nucléotides (ou de bases, par
abus de langage), 1000 nucléotides représentant un « kilobase », 1 million de nucléotides, un
« mégabase ».
A titre d’exemple, la « taille » de l’ADN humain est de 3.2 milliards de nucléotides (fois 2 puisqu’il y a
2 brins), donc 3200 mégabases ou 3.2 gigabases , mais le haricot possède lui un ADN double brin long
de près de 12 milliards de nucléotides (donc 12 gigabases) !
Les 2 brins en orientation inverse sont en plus dits « complémentaires ». En effet l’association entre 2
brins d’ADN pour former une double hélice n’est possible que si les bases opposées s’associent selon
un mode particulier, par liaisons hydrogène faibles (non covalentes).
Ainsi, en face d’un A, on ne peut trouver que T, et vice-versa : A est complémentaire de T.
De même en face de C, on ne peut que trouver G et vice-versa : C est complémentaire de G.
Ce principe est fondamental et universel, il s’appelle la complémentarité des bases et il permet
notamment la conservation de l’information génétique.
La séquence >AGGCTT> d’un brin ne peut donc s’associer qu’avec la séquence <AAGCCT< de l’autre
brin (on lit dans l’autre sens, et on prend la base complémentaire).
Il peut exister parfois d’autres associations de bases, mais dans ce cas là, ce n’est pas une association
complémentaire parfaite, et la double hélice ne revêt pas une forme régulière.
Au final, on arrive donc à la représentation bidimensionnelle étudiée en cours, où la
complémentarité des bases est illustrée schématiquement par des formes qui s’emboîtent : on voit
bien que A ne pourrait pas s’emboîter avec C ni avec G.
Les 2 chaînes sucre/phosphate qui sont de chaque côté en orientation antiparallèle forment l’axe.
Les « paires de bases » au centre sont des structures planes, perpendiculaires à l’axe.
La double hélice s’enroule sur la droite, dans le sens horaire afin de former la torsade observée au
début de ce chapitre.
Le principe de complémentarité des bases est universel, il est intrinsèque à la structure même de
l’ADN. Il assure la conservation de l’information génétique : il est mis en jeu dans la production des
protéines, dans la multiplication des cellules, dans de nombreux autres processus.
Il permet d’expliquer comment une cellule mère peut produire 2 cellules filles génétiquement
identiques lors de la mitose.
La longueur de la molécule d’ADN (le nombre de paires de nucléotides), mais surtout leur ordre, est
caractéristique d’une espèce.
En 2003, l’ensemble de la séquence de l’ADN de l’espèce humaine a été établi, ce qui signifie
qu’aujourd’hui on connaît l’enchaînement des 3.2 milliards de nucléotides qui composent notre
patrimoine génétique (ou presque). Le programme qui a débouché sur ce résultat est l’un des plus
ambitieux programmes scientifiques jamais conçu. Il a réuni dans un même but des centaines de
scientifiques dans des dizaines de laboratoires à travers le monde pendant une douzaine d’années,
en un consortium appelé HUGO : HUman Genome Organization.
En général, comme sur cet exemple, on ne représente la séquence que d’un des 2 brins d’ADN.
Pour représenter le 2e brin, il suffit d’appliquer le principe de complémentarité des bases.
Par exemple le début de cette séquence serait :

Texte du cours de Génétique – Dr Patrice Bourgeois & Pr Nicole Philip
5
IFSI UE2.2S1
– Année 2012-2013 – Génétique Bourgeois
>TTCATCACCCCTCG…>
<AAGTAGTGGGGAGC…<
Nous n’allons pas aborder en détail dans ce cours l’étude des bactéries (procaryotes).
Toutefois, il faut signaler que l’ADN des procaryotes est particulier.
D’abord, les bactéries n’ont pas de noyau. Leur ADN est donc dans le cytoplasme, en général associé
à une structure primitive appelée mésosome.
Les bactéries n’ont en général qu’un seul chromosome, qui est circulaire et d’assez petite taille (1 à
10 millions de nucléotides).
Nous expliciterons cela plus tard, mais il faut également signaler que l’ADN des bactéries ne possède
pas d’introns, et que souvent, les gènes qui participent à un même processus sont organisés en
clusters, l’un derrière l’autre. On appelle cela un opéron.
« l’ADN est dans le noyau des eucaryotes » Cette vue schématique est fausse, car si elle illustre que
chacune des cellules du corps contient l’ensemble de l’information génétique dans son noyau, c’est-
à-dire l’ensemble des chromosomes, ou les 3.2 milliards de paires de nucléotides, il contient 2
erreurs majeures.
Tout d’abord, on n’observe jamais l’ADN « nu », mais toujours recouvert de protéines qui le
protègent et servent à l’organiser et à l’utiliser.
L’ADN n’est pas une molécule autonome.
D’autre part, on n’observe jamais les chromosomes « ordonnés » comme cela, puisque les
chromosomes ne sont visibles qu’à un moment particulier de la vie de la cellule, lorsqu’elle entre en
mitose. Le reste du temps (pendant toute l’interphase), la double hélice recouverte de protéines
forme une espèce de pelote occupant tout le noyau, indiscernable à l’œil ou même au microscope.
En réalité, la double hélice est en association constante avec de nombreuses protéines, qui l’aident à
se replier pour occuper un volume minimal.
L’ensemble ADN + protéines associées constitue ce que l’on appelle la chromatine.
De cette façon, seules les régions « transcriptionnellement actives », c’est-à-dire celles contenant des
gènes en activité, sont « dépliées », les autres étant très condensées ou compactées.
Ainsi, le niveau de condensation de la fibre de chromatine reflète le niveau d’utilisation des gènes de
cette région.
Le niveau maximal de condensation de la chromatine est le chromosome, chromatine ultra-
compactée visible en microscopie optique. A ce moment là, pendant la mitose, aucune lecture des
gènes n’est possible, les nucléotides ne sont plus du tout accessibles.
Plusieurs définitions du génome sont plus ou moins synonymes selon le point de vue. Il s’agit
littéralement de l’ensemble de tous les gènes d’un individu. Mais dans l’espèce humaine, les gènes
ne représentent qu’une petite partie de l’ADN (moins de 20% avec leurs séquences régulatrices). Le
reste est appelé séquences intergéniques. Ces séquences permettent le fonctionnement correct des
gènes et aussi l’évolution. Elles font donc partie intégrante du « patrimoine génétique ».
Si l’on considère l’ensemble des gènes et des séquences intergéniques, on couvre les chromosomes,
qui sont un état particulier de la chromatine pendant la division cellulaire, mais qui permettent de
repérer grossièrement la région dont on parle.
C’est pourquoi usuellement, les gènes sont d’abord identifiés par leur position sur un
« chromosome ».
Hormis le génome particulier de la mitochondrie, déjà évoqué et dont on ne parlera pas plus, le
patrimoine génétique est localisé dans le noyau des cellules eucaryotes. On parle donc de génome
nucléaire.
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
1
/
20
100%