ـــــــ ــ ـ ـ ا ــــــ ـــ او ... République Algérienne Démocratique et Populaire

République Algérienne Démocratique et Populaire
ـــــــــــا ـــــــــاو ــــــــــا ـــــــــا ةرازو
Ministère de l’Enseignement Supérieur et de la Recherche Scientif
ique
UNIVERSITE DES SCIENCES ET DE LA TECHNOLOGIE d’ORAN Mohamed Boudiaf
Faculté des Sciences
Département d’informatique
Spécialité : Informatique Option : Reconnaissance des
formes et intelligence artificielle
MÉMOIRE
Présenté par
Mr. MAIZA Mohammed
Pour l'obtention du diplôme de Magister en Informatique
Thème
Devant la commission d'examen composée de :
Qualité Nom et Prénoms Grade Etb d'origine
Président
Mr.
BENYETTOU Abdelkader
Professeur USTO(MB)
Rapporteur Mr.
BENYETTOU Mohamed
Professeur
USTO(MB)
Examinatrice Mme. HADJ SAID Naïma
Professeur
USTO(MB)
Examinatrice Mme. FIZAZI Hadria
M.conf. A
USTO(MB)
Examinateur Mr.
BELKADI Khaled
M.conf. A
USTO(MB)
Année universitaire :
2011-2012
ANALYSE DES IMAGES AÉRIENNES PAR LES
TECHNIQUES D‘OPTIMISATION

Remerciements
Je remercie…
Dieu de m'avoir illuminé et guidé sur le chemin du bien…
Mon remerciement le plus chaleureux va principalement à mon encadreur
M
r
BENYETTOU Mohamed professeur à l’USTOMB qui m'a orienté, guidé et soutenu
sans hésitation ni relâche dans le choix et l'accomplissement de ce thème.
Je remercie et, au même titre notre guide et président du jury M
r
BENYETTOU
Abdelkader professeur à l'USTOMB et responsable de l'option RFIA pour sa présence
honorable dans les moments les plus émotifs.
Mes remerciements vont également à M
r
BELKADI Khaled maitre de conférences à
l'USTOMB et responsable de l'option MOEPS pour son dévouement et sa compétence.
Je remercie M
me
HADJ SAID Naïma professeur à l'USTOMB pour sa disponibilité,
ses contributions, ses encouragements, sa générosité, et ses précieux conseils et
orientations.
Mes très sincères remerciements vont également à M
me
FIZAZI Hadria maitre de
conférences à l'USTOMB et responsable de l’option TATIDS, à qui j'exprime toute ma
gratitude et ma reconnaissance.
Je remercie tous mes professeurs chacun par son nom pour leur patience et leur
abnégation tout au long de mes études.
Enfin je remercie tout le cadre pédagogique et administratif qui sans eux ma mission ne
se serait pas accomplie.

Dédicaces
Je dédie ce noble travail …
…à, mes parents: à mon père et à ma mère qui m'ont
soutenu et encouragé dans les moments les plus
difficiles.
…à mes frères et à ma sœur pour leur patience et
leur affection.
…à toute ma famille et à tous mes amis.
Mohammed

TABLE DES MATIERES
Introduction générale
CHAPITRE I
« Imagerie Aérienne »
1. Introduction…………………………………………………………………………….....10
2. Historique…………………………………………………………………………………10
3. Les applications de la photographie aérienne……………………………………………..12
4. Concepts de base de la photographie aérienne……………………………………………12
5. Les différents types de photographie aérienne……………………………………………17
6. Moyens de prise de vue…………………………………………………………………...18
6.1. Moyens classiques……………………………………………………………….....18
6.1.1. Avion ou hélicoptère………………………………………………………….18
6.1.2. Cerf-volant……………………………………………………………………19
6.1.3. Photographie en para moteur…………………………………………………20
6.2. Moyens innovants………………………………………………………………......20
6.2.1. Ballon et mât………………………………………………………………….20
6.2.2. Photographie par ballon captif……………………………………………......21
6.2.3. Les drones…………………………………………………………….............21
6.2.4. Les drones de nouvelle génération……………………………………….......23
7. Interprétation des photographies aériennes…………………………………………….....24
8. Traitement et analyse d’image aériennes…………………………………………………29
8.1. Problème de la représentation………………………………………………………30
8.2. Segmentation…………………………………………………………………….....31
8.2.1. Approche contour………………………………………………………..…...32
8.2.2. Approche région……………………………………………………………...32
8.2.3. Coopération…………………………………………………………………..33
8.3. Classification…………………………………………………………………….....33
9. Conclusion………………………………………………………………………………...34
CHAPITRE II
« Systèmes Immunitaires Naturels »
1. Introduction…………………………………………………………………………….....36
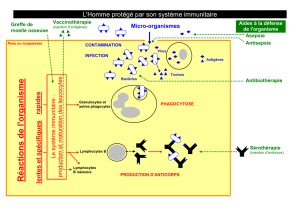
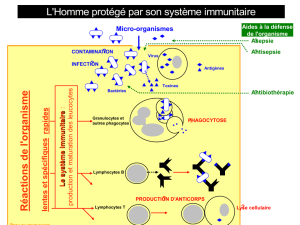
2. Le système immunitaire naturel……………………………………………………..........37
3. Eléments de la machinerie immunologique……………………………………………….39
3.1. Les organes…………………………………………………………………………39
3.2. Les substances……………………………………………………………………...40
3.3. Les cellules…………………………………………………………………………41
3.3.1. Les granulocytes……………………………………………………………...42
3.3.2. Les monocytes et les macrophages…………………………………………...43
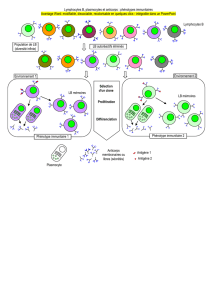
3.3.3. Les lymphocytes……………………………………………………………...44
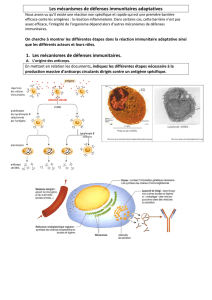
4. Reconnaissance du soi et du non soi……………………………………………………...46
5. Fonctionnement du système immunitaire…………………………………………………47
6.Différents types d’immunité…………………………………………………………….....48
6.1.Immunité non spécifique ou naturelle………………………………………………48

6.2.Immunité spécifique ou adaptative …………………………………………………49
7. Le vaccin………………………………………………………………………………......50
8. Le SIDA…………………………………………………………………………………...50
9. Conclusion………………………………………………………………………………...52
CHAPITRE III
« Systèmes Immunitaires Artificiels »
1. Introduction…………………………………………………………………………….....54
2. Histoire des SIA…………………………………………………………………………...54
3. L’utilisation des SIA pour la reconnaissance des formes…………………………………55
4. Principes de base sur la représentation des données………………………………………56
4.1. Le codage binaire………...…………………………………………………............56
4.2. Le codage réel………………………………………………………………………56
4.3. L’affinité……………………………………………………………………………56
4.4. Le clonage……………………………………………………………………….....56
4.5. La mutation…………………………………………………………………………57
5. Les algorithmes du Système Immunitaire Artificiel………………………………………57
5.1. La sélection négative…………………………………………………………….....58
5.2. La théorie du danger…………………………………………………………..........60
5.3. La sélection clonale………………………………………………………………...61
5.4. Les réseaux immunitaires……………………………………………………..........65
6. Conclusion………………………………………………………………………………...67
CHAPITRE IV
« SVM-Kmeans »
1. Introduction…………………………………………………………………………..…....69
2. Séparateurs à vaste marge………….…………………………………………….....……..70
2.1. Notion de base…………………………………………………..…………..……...70
2.1.1. Hyperplan, marge et support vecteur………………………………….……...70
2.1.2. Maximisation de la marge…………………………………………….……...71
2.2. SVM linéaire……………………………………………………...…………..…….72
2.3. SVM non linéaire…………………….…………………………...…………..…….73
2.4. Application des SVM aux problèmes de classification binaire…………..….……..73
2.4.1. SVM linéaire……………………………..……………………...…...………73
2.4.2. SVM non linéaire……………………………………………………………..77
2.4.3. La marge douce……………………………………………………………….80
2.5. Application des SVM à la classification multi-classes……………………………..81
2.5.1. Un contre un………………………………………………………………….81
2.5.2. Un contre tous……………………..…………..………………...………..….82
3. La méthode Kmeans………………………………...…………………………………….82
4. Conclusion……………………………………………………………………..………….85
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
1
/
111
100%