La_selection_des_services_web_a_base_des_systemes_immunitaires_artificiels_CLONALG.pdf

République Algérienne Démocratique et Populaire
Université Abou Bakr Belkaid
pour l’obtention du
Optio
La sélection des services web à base
des systèmes immunitaires artificiels
Réalisé par :
-
Djelmoudi Abdelhamid
-
Belaredj Mohammed Amin
Présenté le 03 Juillet
201
-
M. Benazzouz Mortada
-
M. Hadjila Fethallah
-
M. Merzoug Mohammed
-
Mlle. Berramdane Djamila
République Algérienne Démocratique et Populaire
Université Abou Bakr Belkaid
– Tlemcen
Faculté des Sciences
Département d’Informatique
Mémoire de fin d’études
pour l’obtention du
diplôme de Master en Informatique
Optio
n:
Modèle Intelligent et Décision(M.I.D)
g{¢Åx
g{¢Åxg{¢Åx
g{¢Åx
La sélection des services web à base
des systèmes immunitaires artificiels
(CLONALG)
Djelmoudi Abdelhamid
Belaredj Mohammed Amin
201
2 devant le jury composé de
M. Benazzouz Mortada
(Président)
M. Hadjila Fethallah
(Encadreur)
M. Merzoug Mohammed
(Examinateur)
Mlle. Berramdane Djamila
(Examinateur)
Année universitaire : 2011-2012
1
République Algérienne Démocratique et Populaire
diplôme de Master en Informatique
La sélection des services web à base
des systèmes immunitaires artificiels
(Examinateur)
(Examinateur)

2
exÅxÜv|xÅxÇàá
exÅxÜv|xÅxÇàáexÅxÜv|xÅxÇàá
exÅxÜv|xÅxÇàá
Nous devons toute chose à DIEU le tout puissant et cela avant tout ; de nous avoir accordé
la force, la chance et la santé pour avoir accompli ce modeste travail.
Ainsi à tous ceux et celles qui ont contribué directement ou indirectement à notre
élaboration de ce mémoire.
Nous remercions M. HADJILA Fethallah notre encadreur qui nous a aidés durant notre
travail.
Nous remercions M. BENAZZOUZ Mortada, M. MERZOUG Mohammed et Mlle.
BERRAMDANE Djamila pour avoir accepté de faire partie du Jury.
Nous adressons nos salutations et nos remerciements à tout nos enseignants pour toutes les
précieuses informations qu’ils nous inculquaient durant nos Travaux et notre cursus.
Nous tenons à adresser également notre gratitude envers le département d’informatique et
tous les membres des équipes du centre de calcul.
Sans oublier nos amis et collègues qui nous ont épaulés durant ce long cursus.
MERÇI

3
W°w|vtvxá
W°w|vtvxáW°w|vtvxá
W°w|vtvxá
Nous Dédions Ce Modeste Travail à :
Nos Parents Qui Nous Ont Beaucoup Aidés Et Encouragés Pour Entamer Ce Long
Chemin d’Etude, Nos Familles Et Nos Proches.
Tous Nos Amis (es), Collègues Et Toute La Promotion De 2
eme
Annee Master
Informatique.
MERCI

4
Sommaire
LISTE DES FIGURES .......................................................... Erreur ! Signet non défini.
LISTE DES TABLES ............................................................ Erreur ! Signet non défini.
INTRODUCTION GENERALE .................................................................................... 10
I. Contexte ............................................................................................................... 12
II. Problématique ...................................................................................................... 12
III. Contribution ..................................................................................................... 12
IV. Plan du mémoire ............................................................................................. 13
Chapitre I
:
Les services web
................................................................................................... 10
I. Introduction ............................................................................................................. 15
II. L’architecture SOA ................................................................................................. 15
1. Couplage faible .................................................................................................... 16
2. Interopérabilité ..................................................................................................... 16
3. Réutilisabilité ....................................................................................................... 17
4. Découverte ........................................................................................................... 17
III. Définitions ........................................................................................................... 18
IV. Architecture des services Web ............................................................................. 18
1. Architecture de base ............................................................................................. 18
2. Architecture en couche ........................................................................................ 19
V. Cycle de vie ............................................................................................................. 22
VI. Les principales technologies de développement de service Web ........................ 23
1. XML (eXtensible Markup Language) ................................................................. 23
2. Le protocole SOAP (Simple Object Access Protocol) ........................................ 25
2.1. Définition ...................................................................................................... 25
2.2. Structure d’un message SOAP ..................................................................... 26
2.3. Fonctionnement ............................................................................................ 27
2.4. Types de message SOAP .............................................................................. 28

5
3. La technologie WSDL (Web Service Description Language) ............................. 30
3.1. Définition ...................................................................................................... 30
3.2. Structure d’un document WSDL .................................................................. 30
4. UDDI - Universal Description Discovery and Integration .................................. 34
4.1. Définition ...................................................................................................... 34
4.2. La recherche d’un service Web .................................................................... 34
4.3. La publication d’un service Web .................................................................. 35
VII. Les avantages et les inconvénients des services Web .......................................... 35
1. Avantages ............................................................................................................. 35
2. Inconvénients ....................................................................................................... 36
VIII. Conclusion ........................................................................................................... 36
Chapitre II :
Sélection des services web ......................................................................... 37
I. Introduction ............................................................................................................. 38
II. Exemple de motivation : (la création d’une entreprise) .......................................... 38
III. Critères de Qos (Quality of service) .................................................................... 39
IV. La fonction objectif (score ou fitness) ................................................................. 40
V. Optimisation combinatoire ...................................................................................... 41
1. Définition ............................................................................................................. 41
2. Approches d’optimisation combinatoire (approches de sélection) ...................... 42
VI. Conclusion ........................................................................................................... 44
Chapitre III:
Les Systèmes Immunitaires ....................................................................... 45
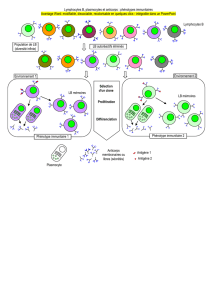
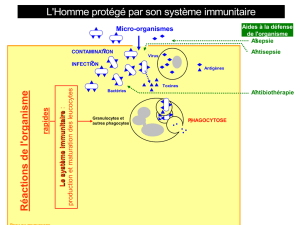
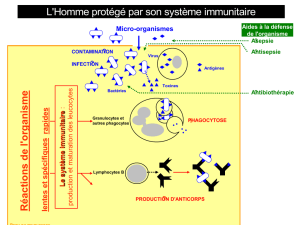
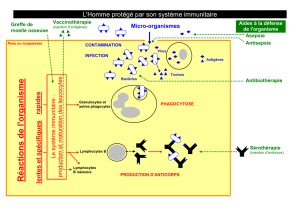
I. Introduction ............................................................................................................. 46
II. Le système immunitaire naturel (SIN) .................................................................... 46
1. L'immunité innée (naturelle non spécifique ou naïve)......................................... 46
2. L'immunité acquise (spécifique) .......................................................................... 46
3. Caractéristique du système immunitaire .............................................................. 47
4. Éléments du système immunitaire ...................................................................... 48
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
1
/
74
100%