Rémy Choquet - Université Lyon 2 - Master 2 IIDEE - 2006-2007

ETL
Extract - Transform - Load
Concept général d’analyse en ligne (rappels)
Rémy Choquet - Université Lyon 2 - Master 2 IIDEE - 2006-2007

Plan
•Définitions
•La place d’OLAP dans une entreprise
•OLAP versus OLTP
•Les règles de Codd
•La construction d’un entrepôt de données
•Requêtes multi-dimensionnelles

Définitions
•Online Analytical Processing (OLAP), désigne les bases de données multidimensionnelles (aussi appelées
cubes ou hypercubes) destinées à l'analyse et il s'oppose au terme OLTP qui désigne les systèmes
transactionnels. Ce terme a été défini par Ted Codd en 1993 au travers de 12 règles que doit respecter une
base de données si elle veut adhérer au concept OLAP.
•Ce concept est appliqué à un modèle virtuel de représentation de données appelé cube ou hypercube
OLAP. Il existe ensuite plusieurs déclinaisons semblables à des drivers qui permettent d'adapter le stockage
des données sur différents types de base de données pour implémenter le concept OLAP :
•R-OLAP (Relational OLAP)
•D-OLAP (Dynamic ou Desktop OLAP)
•M-OLAP (Multidimensional OLAP)
•H-OLAP (Hybrid OLAP)
•S-OLAP (Spatial OLAP)
Source: Wikipédia
0
25
50
75
100
2004 2005 2006 2007

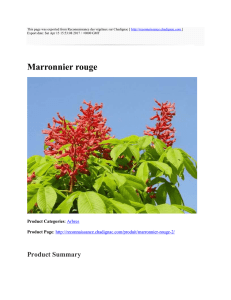
OLAP en entreprise (décisionnel) 1/3
•L’informatique décisionnelle (en anglais : DSS pour Decision Support System ou encore BI pour Business
Intelligence) désigne les moyens, les outils et les méthodes qui permettent de collecter, consolider,
modéliser et restituer les données d'une entreprise en vue d'offrir une aide à la décision et de
permettre aux responsables de la stratégie d'une entreprise d’avoir une vue d’ensemble de l’activité
traitée. Ce type d’application utilise en règle générale un datawarehouse (ou entrepôt de données) pour
stocker des données transverses provenant de plusieurs sources hétérogènes et fait appel à des
traitements lourds de type batch (sans ETL) pour la collecte de ces informations.
•L’informatique décisionnelle s’insère dans l’architecture plus large d’un système d'information.
•Les applications classiques « d’entreprise » permettent de stocker, restituer, modifier les données des
différents services opérationnels de l’entreprise (production, marketing, facturation comptabilité, etc.).
Ces différents services possèdent chacun une ou plusieurs applications propres, et les données y sont
rarement structurées ou codifiées de la même manière que dans les autres services. Chaque service
dispose le plus souvent de ses propres tableaux de bord et il est rare que les indicateurs (par exemple :
le chiffre d'affaires sur un segment de clientèle donné) soient mesurés partout de la même manière,
selon les mêmes règles et sur le même périmètre.
•Pour pouvoir obtenir une vision synthétique de chaque service ou de l’ensemble de l’entreprise, il
convient donc que ces données soient filtrées, croisées et reclassées dans un entrepôt de données
central. Cet entrepôt de données va permettre aux responsables de l’entreprise et aux analystes de
prendre connaissance des données à un niveau global et ainsi prendre des décisions plus pertinentes,
d’où le nom d’informatique décisionnelle.
Source: wikipédia

•Les données applicatives métier sont stockées dans une (ou plusieurs) base(s) de données relationnelle(s) ou non
relationnelles.
Ces données sont extraites, transformées et chargées dans un entrepôt de données généralement par un outil de type
ETL (Extract-Tranform-Load) ou en français ETC (Extraction-Tranformation-Chargement)
•Un entrepôt de données peut prendre la forme d’un datawarehouse ou d’un datamart. En règle générale, le
datawarehouse globalise toutes les données applicatives de l’entreprise, tandis que les datamarts (généralement alimentés
depuis les données du datawarehouse) sont des sous-ensembles d’informations concernant un métier particulier de
l’entreprise (marketing, risque, contrôle de gestion, ...). Le terme comptoir de données ou magasin de données est aussi
utilisé pour désigner un datamart.
•Le reporting est vraisemblablement l'application la plus utilisée encore aujourd'hui de l’informatique décisionnelle, il
permet aux gestionnaires!:
•de sélectionner des données relatives à telle période, telle production, tel secteur de clientèle, etc.,
•de trier, regrouper ou répartir ces données selon les critères de leur choix,
•de réaliser divers calculs (totaux, moyennes, écarts, comparatif d'une période à l'autre, ...),
•de présenter les résultats d’une manière synthétique ou détaillée, le plus souvent graphique selon leurs besoins ou
les attentes des dirigeants de l’entreprise.
•Les programmes utilisés pour le reporting permettent bien sûr de reproduire de période en période les mêmes sélections
et les mêmes traitements et de faire varier certains critères pour affiner l’analyse. Mais le reporting n'est pas à
proprement parler une application d'aide à la décision. L'avenir appartient plutôt aux instruments de type tableau de bord
équipés de fonctions d'analyses multidimensionnelles de type Olap.
•Les datamart et/ou les datawarehouses peuvent aussi alimenter des bases de données multidimensionnelles, qui
permettent l’analyse très approfondie de l’activité de l’entreprise, grâce à des statistiques recoupant des informations
relatives à des activités apparemment très différentes ou très éloignées les unes des autres, mais dont l’étude fait souvent
apparaître des dysfonctionnements, des corrélations ou des possibilités d’améliorations très sensibles.
•L'interopérabilité entre les systèmes d'entrepôt de données, les applications informatiques ou de gestion de contenu, et les
systèmes de reporting est réalisée grâce à une gestion des métadonnées.
OLAP en entreprise (décisionnel) 2/3
Source: wikipédia
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
1
/
26
100%