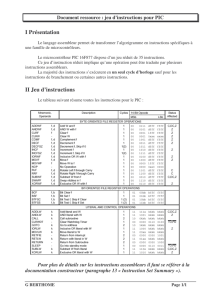
Additionneur par propagation de retenue

Circuits et architecture des ordinateurs
Année 2008/2009
Université Paris Diderot
Olivier Carton
Version du 8 Dec 2008


1 Circuits et architecture des ordinateurs en M1
Cours le lundi en salle 470E (halle aux farines) de 8h30 à 10h30
Cours du lundi 10 novembre déplacé au mercredi 12 novembre de 12h30 à 14h30 en salle 473F
Bibliographie
Travaux dirigés (tkgate version 1.8.7)
mardi en salle 470E ou T de 10h30 à 12h30 (I. Fagnot)
mardi en salle 470E ou T de 12h30 à 14h30 (A. Micheli)
Ce support de cours en PDF
Processeur LC3
Références
Années 2006/2007 et 2007/2008
Présentation du cours
Cours n° 1 : historique et représentation des données
galeries de photos
entiers
entiers signés
Cours n° 2 : représentation des données (suite), transistors, portes
réels (norme IEEE 754)
caractères (ASCII et Unicode)
logique de Boole
table de vérité
tableaux de Karnaugh
transistors
portes logiques (inverseur, nand, nor)
Cours n° 3 : additionneurs
circuits élémentaires
additionneurs
semi-additionneur
additionneur complet
additionneur par propagation de retenue (ripple-carry adder)
calcul des indicateurs
soustraction
Cours n° 4 : additionneurs (suite)
additionneur par anticipation de retenue (carry-lookahead adder)
additionneur récursif
additionneur hybride
additionneur par sélection de retenue
Cours n° 5 : mémoire
mémoire statique/mémoire dynamique
bascule RS
bascule D
mémoire 4 × 3 bits
Cours n° 6 : circuits séquentiels et architecture générale d’un micro-processeur
principe des circuits séquentiels
construction d’une guirlande
- 1 -

cas d’un automate fini
modèle de von Neumann
unité de contrôle
unité de traitement
mémoire
Cours n° 7 : description du LC-3
registres
organisation de la mémoire
jeu d’instructions du processeur LC-3
chemins de données du LC-3
Cours n° 8 : programmation en assembleur du LC-3
longueur d’une chaîne
mutiplication non signée, signée et logarithmique
addition 32 bits
Cours n° 9 : appels de sous-programmes, pile
appels de sous-programme
pile
sauvegarde des registres
tours de Hanoï
Cours n° 10 : appels systèmes et interruptions
entrées/sorties
appels systèmes
interruptions
Cours n° 11 : autres architectures
processeurs 80x86
comparaison CISC/RISC
architecture IA-64
Cours n° 12 : pipeline
principe
étages
réalisation
aléas
Cours n° 13 : gestion de la mémoire
mémoires associatives
mémoire virtuelle
mémoires cache
Examen le 15 janvier de 15h30 à 18h30 en amphi 11E (halle aux farines)
- 2 -

2 Historique
2.1 Historique général
Quelques dates clés
500 av JC
apparition des bouliers et abaques
1632
invention de la règle à calcul
1642
Pascal invente la Pascaline
1833
machine de Babbage
1854
publication par Boole d’un ouvrage sur la logique
1904
invention du tube à vide
1937
article d’Alan Turing sur la calculabilité : machines de Turing
1943
création du ASCC Mark 1 (Harvard - IBM) : Automatic Sequence-Controlled Calculator
1946
construction de l’ENIAC
1947
invention du transistor (Bell)
1955
premier ordinateur à Transistors : TRADIC (Bell)
1958
premier circuit intégré (Texas Instrument)
1964
langage de programmation BASIC
1965
G. Moore énonce la loi qui porte son nom : loi de Moore
1969
système d’exploitation MULTICS puis UNIX (Bell)
1971
premier microprocesseur : 4004 d’Intel (4 bits, 108 KHz, 2300 transistors)
1972
microprocesseur 8008 d’Intel (8 bits, 200 KHz, 3500 transistors)
1973
langage C pour le développement d’UNIX
1974
premier microprocesseur Motorola : 6800 (8 bits)
1974
microprocesseur 8080 d’Intel
- 3 -
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
1
/
139
100%