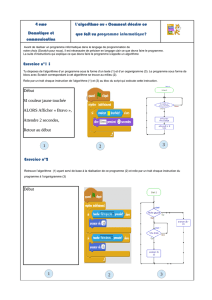
L`algorithme path-repair





 6
7
8
6
7
8
1
/
8
100%
6
7
8