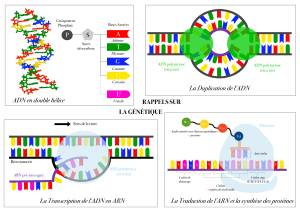
Biochimie : Acides nucléiques, Réplication, Transcription

Biochimie - Acides nucléiques : structure et réplication, transcription et traduction
BIOCHIMIE
BIOCHIMIE
Cours 1 et 2 – Acides nucléiques : structure et réplication,
transcription et traduction
Pr Denamur
Ce document est un support de cours datant de l’année 2014-2015 disponible sur www.tsp7.net 1
I. Un acide nucléique consiste en 4 types de bases liées par un squelette sucre-phosphate
A. L’ARN et l’ADN diffèrent par le sucre et une des bases
B. Les nucléotides sont les unités monomériques des acides nucléiques
II. Une paire de chaînes d’acide nucléique avec des séquences complémentaires peut
former une double hélice avec une séquence complémentaire
A. La double hélice est stabilisée par des liaisons hydrogène
B. La double hélice facilite la transmission de l’information héréditaire
C. La double hélice peut être dénaturée de façon réversible
D. Les acides nucléiques simple-brin peuvent adopter des structures élaborées
III. L’ADN est répliqué par des polymérases qui prennent leur instruction sur des matrices
A. Les ADN polymérases nécessitent une matrice et une amorce
B. La réplication de l’ADN se fait rapidement à partir de sites spécifiques
IV. L’expression génique est la transformation de l’information de l’ADN en molécules
fonctionnelles
A. Plusieurs types d’ARN jouent un rôle clé dans l’expression
B. Tous les ARN sont synthétisés par des ARN polymérases
C. Les ARN polymérases prennent leurs instructions à partir des matrices d’ADN
D. La transcription débute près des sites promoteurs et se termine à des sites terminateurs
E. L’ARNt est une molécule adaptatrice dans la synthèse des protéines
V. Les acides aminés sont codés par des groupes de 3 bases à partir d’un point fixe
A. Les principales caractéristiques du code génétique
B. L’ARNm contient des signaux de début et de fin pour la synthèse des protéines
VI. La plupart des gènes eucaryotes sont des mosaïques d’introns et d’exons
A. L’épissage de l’ARNm génère l’ARN mature
B. De nombreux exons codent pour des domaines protéiques

Biochimie - Acides nucléiques : structure et réplication, transcription et traduction
I. UN ACIDE NUCLÉIQUE CONSISTE EN 4 TYPES DE BASES
LIÉES PAR UN SQUELETTE SUCRE-PHOSPHATE
Les acides nucléiques sont les porteurs de l’information génétique. On en distingue 2 types :
•ADN : acide désoxyribonucléique
•ARN : acide ribonucléique
Ce sont des polymères linéaires faits d’unités similaires (différent de « identique ») connectées entre
elles. Chaque unité monomérique est composée de 3 constituants : sucre, phosphate, base. La séquence
des bases caractérise un acide nucléique et représente une forme d’information linéaire.
A. L'ARN et l'ADN diffèrent par le sucre et une des bases
Le sucre dans l’ADN est le désoxyribose. Le préfixe « désoxy » indique que le C en 2’ n’a pas d’atome
d’oxygène à l’inverse du ribose, le sucre de l’ARN. On met des ‘ sur les C pour les distinguer de ceux des
bases.
Les sucres dans les acides nucléiques sont liés entre eux par des liaisons phosphodiester. Une liaison
ester se fait entre un acide (phosphorique ici = phosphate) et un alcool (OH), ici on a 2 liaisons ester, d'où le
« diester ». Le groupe 3’OH d’un sucre d’un nucléotide est estérifié par un groupe phosphate qui est joint
au groupe OH en 5’ du sucre adjacent.
Chaque liaison phosphodiester porte une charge négative qui repousse les espèces nucléophiliques,
comme les ions hydroxydes, susceptibles d'hydrolyser la liaison. Ceci permet la protection de l'intégrité de
l'information génétique. Cette liaison est aussi appelée liaison ester phosphorique.
La chaîne des sucres liés par les liaisons phosphodiester représente le squelette de l’acide nucléique.
Sur ce squelette sont fixées les bases : puriques, dérivant d’un noyau purine (Adénine, Guanine) et
pyrimidiques, dérivant d’un noyau pyrimidine (Uracile, Thymine, Cytosine). Les bases sont des hétérocycles
aromatiques
(ou azotés).
3 à 8% des cytosines sont méthylées sur le C5 chez les eucaryotes, ce qui donne de la 5-méthylcytosine
(il a dit qu'il en reparlera plus tard dans le cours). L'uracile est une base de l'ARN et la thymine, une base de
l'ADN, seule la cytosine est commune à l'ADN et l'ARN parmi les bases pyrimidiques.
Ce document est un support de cours datant de l’année 2014-2015 disponible sur www.tsp7.net 2

Biochimie - Acides nucléiques : structure et réplication, transcription et traduction
Formule des bases avec la numérotation des atomes :
Les bases puriques sont structurellement plus complexes que les bases pyrimidiques.
Les atomes sont numérotés sans ‘ par convention. L’absence du groupement OH en 2’ de l’ADN
augmente sa résistance à l’hydrolyse. Cette plus grande stabilité de l’ADN explique probablement son
utilisation plutôt que l’ARN comme matériel héréditaire dans toutes les cellules modernes et beaucoup de
virus.
L'ARN a un groupement hydroxyle en 2' qui va permettre la liaison phosphodiester 2'-5', importante
pour l'excision des introns.
B. Les nucléotides sont les unités monomériques des acides nucléiques
L'unité formée d'une base liée à un sucre est appelée nucléoside. Les 4 nucléosides de l’ARN sont
adénosine, guanosine, cytidine, uridine. Ceux de l’ADN sont désoxyadénosine, désoxyguanosine,
désoxycytidine, thymidine (on ne parle pas de «désoxythymidine» car la thymine est forcément associée à
un désoxyribose). Dans tous les cas, c’est le N9 de la purine et le N1 de la pyrimidine qui sont liés au C-1’
du sucre.
*monomère = un seul
Exemple :
Les nucléotides:
Un nucléotide est un nucléoside lié à un ou plusieurs groupes
phosphate par une liaison ester : on a alors un nucléoside-5’-
phosphate.
Exemple:
ATP= adénosine 5’ tri-phosphate (transporteur d’énergie)
Le professeur a aussi dessiné la structure du Désoxyguanosine 5' mono-phosphate (dGMP)
Ce document est un support de cours datant de l’année 2014-2015 disponible sur www.tsp7.net 3

Biochimie - Acides nucléiques : structure et réplication, transcription et traduction
Les 4 unités nucléotidiques de l’ADN sont :
•dAMP : désoxyadénosine-5'-monophosphate
•dGMP : désoxyguanosine-5'-monophosphate
•dCMP : désoxycytosine 5' monophosphate
•TMP :thymidine 5' monophosphate
Celles de l’ARN sont :
•AMP : adénosine-5'-monophosphate
•GMP
•CMP
•UMP
pApCpG ou pACG = trinucléotide d’ADN composé de dAMP, dCMP et dGMP liés par des liaisons
phosphodiesters.
L’extrémité 5’ aura un phosphate attaché au groupe 5’-OH. Comme pour un polypeptide, la chaîne
d’ADN a une polarité : une extrémité de la chaîne a un groupe 5’-OH attaché à un phosphate, alors que
l’autre extrémité a un groupe 3’-OH qui peut être lié à un autre nucléotide.
Par convention, la séquence des bases est notée 5’ vers 3’. ACG veut donc dire que 5’-OH non-lié est
celui du dAMP, celui du 3’-OH non-lié sur le dGMP. À cause de cette polarité, ACG et GCA sont des
composés différents.
Une caractéristique étonnante des molécules d’ADN
naturelles est leur taille.
•Virus : 5000 paires de bases.
•Escherichia coli : 4-6 106 paires de bases (ADN
circulaire)
•Homme : 3 109 paires de bases divisées en 24
molécules (chromosomes) distinctes (22
autosomes, X et Y) de tailles différentes (ADN «linéaire»)
•Daim : une molécule d'ADN comporte plus un milliard de paires de base.
II. UNE PAIRE DE CHAÎNES D’ACIDES NUCLÉIQUES PEUT
FORMER UNE DOUBLE HÉLICE AVEC UNE SÉQUENCE
COMPLÉMENTAIRE
La structure covalente des acides nucléiques rend compte de leur capacité à porter une information
sous la forme d’une séquence de bases le long de la chaîne d’acide nucléique. La possibilité de former des
paires de bases spécifiques de telle façon qu’une structure secondaire en hélice se forme facilite la
réplication (génération de 2 copies à partir d’une) du matériel génétique.
Importance de transmettre l'information génétique aux générations suivantes sans trop la modifier.
Ce document est un support de cours datant de l’année 2014-2015 disponible sur www.tsp7.net 4

Biochimie - Acides nucléiques : structure et réplication, transcription et traduction
A. La double hélice est stabilisée par des liaisons hydrogènes
Franklin et Wilkins, dans les années 50, obtiennent une photo de la diffraction aux rayons X de l’ADN, ce
qui entraîne la découverte par Watson et Crick de la structure en double hélice en 1953. Deux chaînes
polynucléotidiques sont enroulées en hélice autour d’un axe commun. Ces chaînes sont en direction
opposée. Les squelettes sucre-phosphate sont en dehors, et les bases à l’intérieur. Les bases sont
perpendiculaires à l’axe de l’hélice et les bases adjacentes sont séparées par 3,4 angströms (1 angström =
0.1 nm). La structure hélicoïdale se répète tous les 34 angströms, soit toutes les 10 bases = 1 tour d’hélice.
Il y a donc une rotation de 36° par bas e (au total 360° pour les 10 bases = un tour complet). Le diamètre de
l’hélice est de 20 angströms. Comment une structure aussi régulière peut elle s’accommoder d’une
séquence arbitraire de bases, étant donné les tailles différentes des purines et des pyrimidines ?
Entre G et C, on a 3 liaisons hydrogènes, contre 2 seulement entre A et T. Cet appariement était
supposé par des études antérieures sur la composition en bases d’ADN de différentes espèces. Chargaff
(1950) démontre que les ratios A/T et G/C sont proches de 1 dans toutes les espèces, alors que le ratio
A/G varie considérablement (1,56 pour l'Homme, 1,67 pour la levure (eucaryote unicellulaire) et 0,7 pour la
bactérie). Ces exemples de ratios A/G ont été écrits par le professeur. Retenir le principe
On appelle cette règle la règle de Chargaff.
Attention, ce sont les bases qui sont appariées spécifiquement et non pas les sucres !
ATTENTION, le sucre que porte la guanine et l'adénine sur ce schéma n'est pas du ribose mais du
désoxyribose
Polymère de nucléotide dans un sens apparié avec un autre polymère dans l'autre sens complémentaire.
B. La double hélice facilite la transmission
de l'information génétique
Le modèle de la double hélice et l'observation d'un
appariement spécifique des bases a immédiatement suggéré la
façon dont le matériel génétique se réplique => réplication semi-
conservative.
Les expériences de Menselson et Stahl (1958) confirment
cette réplication semi-conservative chez E. coli par marquage de
l’ADN parental avec un isotope lourd de l’azote, 15N, pour le
rendre plus dense que l’isotope naturel 14N.
Ce document est un support de cours datant de l’année 2014-2015 disponible sur www.tsp7.net 5
 6
7
8
9
10
11
12
13
14
6
7
8
9
10
11
12
13
14
1
/
14
100%