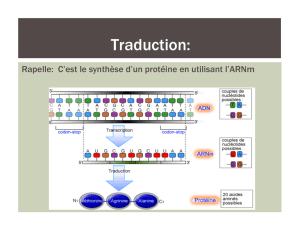
séquence d`acides aminés

Dr Stéphan Clavel
Biochimie - Physiologie
stephan.clavel@unice.fr
04.92.07.68.93
LABORATOIRE DE BIOLOGIE CELLULAIRE & MOLECULAIRE
UMR-CNRS 6548
«Signalisation et différentiation des cellules musculaires»
MASTER 1 STAPS

1. Introduction Générale
Les protéines ont une durée de vie limitée (entre quelques min à quelques jours)
elles doivent être renouvelées en permanence
- « Entretien »
- Croissance
- Cicatrisation
Localisation des processus
Rq: certaines protéines de la
matrice extracellulaire sont
connues pour leur longévité
(plusieurs années).
•Synthèse (assemblage des acides
aminés en chaîne polypeptidique =
protéine): ribosomes
•Processus de dégradation intracellulaire: protéasome et lysosomes

1. Rappel: Information génétique
50% du poids sec de la plupart
des cellules = protéines
•Protéine = polymère
(chaîne) d'acides aminés
Nombre total de protéines
que peut fabriquer
l'organisme humain ???
•Chaque protéine est caractérisée par sa séquence d'acides aminés.
Ex. le lysozyme (126 AA)
Lys-Val-Phé-Gly-Arg-Cys-Glu-Leu-Ala-Ala-Ala-Met-Lys-Arg-His-Gly-Leu-Asp-
Asn-Tyr-Arg-Gly-Tyr-Ser-Leu-Gly-Asn-Trp-Val-Cys-Ala-Ala-Lys-Phe-Glu-Ser-
Asn-Thr-Gln-Ala-Thr-Asn-Arg-Asn-Thr-Asp-Gly-Ser-Thr-Asp-Tyr-Gly-Ilu-Leu-
Gln-Ilu-Asn-Ser-Arg-Trp-Trp-Cys-Asn-Asp-Gly-Arg-Thr-Pro-Gly-Ser-Arg-Asn-
Leu-Cys-Asn-Ilu-Pro-Cys-Ser-Ala-Leu-Leu-Ser-Ser-Asp-Ilu-Thr-Ala-Ser-Val-
Asn-Cys-Ala-Lys-Lys-Ilu-Val-Ser-Asp-Gly-Asp-Gly-Met-Asn-Ala-Trp-Val-Trp-
Arg-Asn-Arg-Cys-Lys-Gly-Thr-Asp-Val-Gln-Ala-Trp-Ilu-Arg-Gly-Cys-Arg-Leu

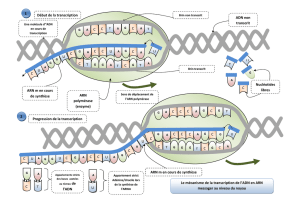
Pour fabriquer une protéine, il faut:
Noyau contient une
matière appelée
chromatine
Chromatine = mélange
de protéines appelées
histones et d'ADN
•Des acides aminés.
•La recette (quels acides aminés il faut assembler et dans quel ordre)

1.1 Structure de l’ADN (Acide DésoxyriboNucléique)
La molécule d ’ADN est composée de 3 types de molécules:
•Groupements phosphate
•Désoxyribose (sucre à 5 carbones)
•Bases azotées:
- Purines: Adénine, Guanine (A, G).
- Pyrimidines: Thymine, Cytosine (T, C).
Sucre
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
1
/
47
100%