Correlation genetique entre performance et distance de course

Corrélations génétiques entre les
performances à différentes distances
de courses chez les pur sang

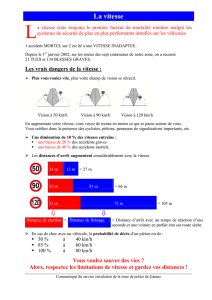
Au brésil les pur-sang de courses courent sur
différentes distances au cours de leur vie: 600à
4000 m ; avec la plupart des courses (90%) qui se
concentrent du 1000 m au 1600 m.
Plusieurs caractères ont été utilisés pour mesurer
les performances en courses des chevaux comme
le classement, les temps mais il existe des
divergences pour savoir lequel est le plus approprié.

Plan d’un hippodrome:

Elaboration de données
L’utilisation de tel ou tel critère peut se baser
uniquement sur la disponibilité des informations du
pays d’origine ou de la race impliquée
Moritsu et al.(1994) Et Oki et al.(1994) Estime que le
temps de course est le seul paramètre direct de la
vitesse et que c’est une donnée quantitative
appropriée qui peut être utilisée pour évaluer les
performances génétiques des chevaux

Oki et al.(1995) : les temps de courses à différentes distances
doivent être considérés comme différents caractères lors de
l’analyse génétique et l’estimation des paramètres génétiques de
ces différentes distances est nécessaire pour élaborer un
programme de sélection.
Cependant l’évaluation génétique à différentes distances altère la
sélection quand des caractères additionnels sont considérés
dans le processus.
C’est pourquoi Oki et al.(1997) ont proposé l’utilisation unique du
caractère temps par 100m pour l’évaluation génétique des pur-
sangs au Japon en raison des corrélations génétiques élevées
(0.85 entre les distances de 1000m à 2000m)
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
1
/
35
100%