Acquisition et évaluation sur corpus de propriétés de sous


D. BOURIGAULT, C FREROT TALN 2005, Dourdan, juin 2005 2
Evaluation des performances d’un analyseur syntaxique
(Syntex),
pour la tâche de résolution des ambiguïtés de
rattachement prépositionnel,
effectuée à l’aide d’un lexique de de sous-catégorisation
acquis sur un corpus d’apprentissage de 200 millions de
mots,
sur des corpus d’évaluation de genre variés
Journalistique, littéraire, juridique, médical
Objectif de l’étude

D. BOURIGAULT, C FREROT TALN 2005, Dourdan, juin 2005 3
Ambiguïté de rattachement prépositionnel
Un problème « classique »
Beaucoup de travaux, depuis (Hindle & Rooth, 1993)
Il voit un homme avec un télescope
il mange une pizza avec des olives
Faire varier les corpus d’évaluation
Gildea (2001) : «Most work in statistical method has focused on a
single corpus: the Wall Street Journal portion of the Penn Treebank »
Kilgarriff & Greffenstette (2003) : « There is little work on assessing
how well one language language model fares when applied to a text
type that is different from that of the training corpus. »
(Basili et al.1999) (Illouz, 1999) (Roland & al., 2000) (Gildea, 2001)

D. BOURIGAULT, C FREROT TALN 2005, Dourdan, juin 2005 4
Méthode de résolution des ambiguïtés de
rattachement prépositionnel
En entrée : une phrase étiquetée, partiellement analysée
1ère étape : rechercher_candidats :
Etant donné une préposition p, qui régit un mot m’, rechercher
dans le contexte gauche l’ensemble des mots mjsusceptibles de
régir la préposition p
des règles qui décrivent dans quelles configurations
conserver un mot comme candidat
« sauter » un mot
arrêter la recherche
2ème étape : choisir_candidat
Sur la base d’indices affectés à chacun des candidats
Principal indice : probabilité que le mot candidat mjse construise
avec la préposition p : proba(mj, p)

D. BOURIGAULT, C FREROT TALN 2005, Dourdan, juin 2005 5
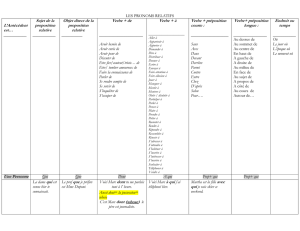
Recherche des candidats
La France défendra ses intérêts avec la plus grande fermeté .
Le problème est triple : insuffisance de la recherche sur des pathologies, …
Son rôle serait de protéger un port ou un dispositif naval en mouvement
On lui proposait des rôles dans des comédies idiotes et des films d'action sans scénario
Certains pays réclament l'élimination totale des subventions agricoles àl' exportation
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
1
/
25
100%