(Pr\351sentation PixInfo 7)

Plan
1. Introduction
2. La chaîne de traitement d'image
3. Seuillage automatique
4. Méthodes de classification
5. Détection de contours
6. Méthodes de type croissance de région

Méthodes de classification
●Principe
–On dispose de plusieurs attributs par pixels
●exemple : R, V, B, µ, σ local, attributs de texture
–Chaque pixel = individu avec attibuts
= vecteur
–On réalise une classification dans l'espace des
attributs
●exemple pour 2 attributs :
C1
C2

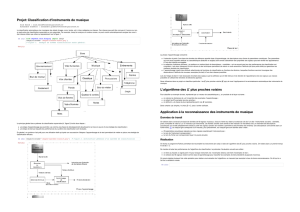
Exemple avec une image couleur
Rouge
Vert
Image couleur originale

Classification supervisée
●Principe
–Ensemble d'apprentissage (individus de classe
connues)
–Découpage de l'espace des attributs
–Classification d'individus inconnus
C1
C2
?
Découpage Individu à classer
Ensemble
d'apprentissage
Ensemble
d'apprentissage

Classification non supervisée
●Principe
–Pas de classes prédéfinies
–Découpage de l'espace selon des critères de
proximité
–Classification des individus
Découpage par proximité Individus à classer
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
1
/
24
100%