cours unix finale

1
SYSTEME D EXPLOITATION UNIX
Chapitre 1 : système d’exploitation ?
Chapitre 2 : Le système de fichiers
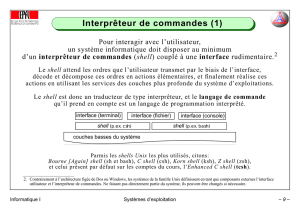
Chapitre 3 : SHELL
Chapitre 4 : Les processus
Chapitre 5 : Quelques outils supplémentaires
Chapitre 6 : Communications sous Unix
Chapitre 7. UNIX et Scripts

2
Chapitre 1 : système d’exploitation ?
1.1 Système informatique: le matériel
1.2 Système informatique: le logiciel
1.3 Objectifs d’un système d’exploitation
1.4 Système multitâche et multi-utilisateur
1.5 Exemple de catégories de systèmes informatiques
1.6 Système d’exploitation Unix
1.7 Historique d’Unix
1.8 Conclusion

3
1.1 Système informatique: le matériel
•
L’objectif d’un système informatique est d’automatiser le traitement de l’information.
•
Un système informatique est constitué de deux entités: le matériel et le logiciel.
•
Côté matériel, un ordinateur est composé de:
o
L’Unité Centrale (UC) pour les traitements
o
La Mémoire Centrale (MC) pour le stockage
o
Les Périphériques: disque dur, clavier, souris, carte réseau... accessibles via des pilotes de
périphériques
1.2 Système informatique: le logiciel
•
Côté logiciel, un système informatique est composé de deux niveaux bien distincts: le système
d’exploitation et les applications.
o
L’objectif du logiciel est d’offrir aux utilisateurs des fonctionnalités adaptées à leurs besoins.
o
Le principe est de masquer les caractéristiques physiques du matériel.
o
La solution consiste à structurer en couches le logiciel, chacune offrant des services de plus
en plus évolués au niveau supérieur.
Cette abstraction logicielle du matériel s’appelle machine virtuelle.

4
1.3 Objectifs d’un système d’exploitation
•
Les deux objectifs majeurs d’un système d’exploitation sont :
1. Transformer le matériel en une machine utilisable, c.-à-d. fournir des outils adaptés aux
besoins des utilisateurs indépendamment des caractéristiques physiques,
2. Optimiser l’utilisation des ressources (matérielles et logicielles).
•
Ces deux objectifs doivent être atteints en garantissant un bon niveau en:
o
Sécurité: intégrité, contrôle des accès, confidentialité...,
o
Fiabilité: satisfaction des utilisateurs même dans des conditions hostiles et imprévues,
o
Performance du système informatique.
1.4 Système multitâche et multi-utilisateur
•
Un système d’exploitation multitâche ré-attribue périodiquement (quantum de temps de l’ordre du
centième de seconde) l’UC à une tâche (exécution d’un programme) différente dans le but de faire
progresser l’exécution de plusieurs programmes à la fois.
o
La notion d’ordonnancement de tâches est alors apparue.
o
L’utilisateur a l’impression que plusieurs programmes sont exécutés « simultanément ».
•
A contrario, un système d’exploitation monotâche exécute une commande uniquement lorsque la
précédente est terminée.
•
Un système multitâche peut permettre à plusieurs utilisateurs de travailler simultanément, il est
alors dit multi-utilisateur.
o
Le système d’exploitation alloue chaque quantum de temps à des programmes de différents
utilisateurs.
o
Ainsi tous les utilisateurs ont l’impression de travailler simultanément (c’est le temps
partagé).
1.5 Exemple de catégories de systèmes informatiques
•
Ordinateurs individuels anciens (catégorisation volontairement obsolète) :
o
Matériel: PC, MacIntosh...
o
Système d’exploitation: DOS, Windows 3.1, Mac OS...
o
Mono-utilisateur et monotâche (ou forme limitée de multitâche)
•
Systèmes informatiques à temps partagé
o
Matériel: Stations de travail, Mini, PC...
o
Système d’exploitation: Unix, VMS, Windows NT/2000/XP/Vista..., Mac OS X...
o
Multi-utilisateur et multitâche.
•
Systèmes informatiques spécialisés
o
Matériel et logiciel spécifiques
Temps réel: robots, contrôle de processus industriels, systèmes informatiques
embarqués...
Transactionnel: réservation de places, service après-vente...
1.6 Système d’exploitation Unix
•
Unix est un système d’exploitation multitâche et multi-utilisateur structuré en couches, garantissant
sa portabilité (existence sur presque toutes les matériels).

5
o
Le noyau Unix contient les principales fonctionnalités du système.
o
La bibliothèque C fait l’interface entre le noyau et les programmes utilisateurs.
o
Unix fournit une interface homme / machine très puissante appelée shell mais aussi des
interfaces graphiques.
o
Unix fournit de nombreux outils (en standard et dans le domaine public).
1.7 Historique d’Unix
•
1960+ Il y a beaucoup de débats sur les mérites des différents langages de programmation (PL/1,
APL, Simula, ALGOL 60, COBOL, FORTRAN, etc.). À l'Université de Londres et de Cambridge, le
langage BCPL (Basic Combined Programming Language) est créé. Des recherches sur les concepts de
temps partagé, de traitement interactif (par opposition au traitement par lots), de pagination et de
protection de la mémoire, d'ordonnancement des travaux et de structure de fichiers sont débutées.
•
1967 Dennis Ritchie quitte Harvard pour travailler aux Laboratoires Bell dans le New Jersey.
•
1968 Ken Thompson quitte Berkeley, où se faisaient déjà des recherches sur un nouveau système
d'exploitation (SDS930), pour se joindre à une équipe de spécialistes qui avaient travaillé sur les
systèmes Multics (Cambridge Multiple Access System) et GE 645.
•
1969 Thompson et Ritchie produisent la première édition d'un système à usager unique sur un PDP
7. C'est un système primitif qui ne comporte qu'un assembleur et un chargeur.
•
1970 La primitive « fork » est ajoutée pour permettre la création de processus et des programmes
utilitaires pour la gestion des fichiers sont produits (deuxième édition). Le système accepte alors
deux usagers et Thompson le baptise UNIX. Ken Kernighan avait, un jour, fait référence au système
par: « Uniplexed Information and Computing System » (UNICS) par opposition à MULTICS
(Multiplexed Information and Computing System).
•
1971 Le système est transporté sur un PDP 11/20 et un système de traitement de textes (roff) est
produit pour le service des brevets des Laboratoires Bell (le premier utilisateur extérieur de UNIX).
Thompson et Ritchie publient la première documentation du système. C'est la troisième édition.
•
1972 UNIX est amélioré en lui ajoutant la notion de relais (pipe). Thompson développe le langage B
(un descendant de BCPL) et réécrit l'assembleur du système en B. C'est un compilateur qui produit
du code interprétable, peu performant et Ritchie produit un générateur de code pour le PDP 11.
C'est le langage C. Il existe à l'époque environ 20 sites utilisant le système UNIX.
•
1973 UNIX est réécrit en langage C (quatrième édition). Il fonctionne alors sur un ordinateur avec un
disque rigide de 500K et peut supporter environ cinq usagers. Thompson se charge de la gestion de
processus tandis que Ritchie s'occupe de la gestion des entrées/sorties.
•
1974 Plusieurs universités commencent à utiliser UNIX et la cinquième édition, conçue spécialement
pour des fins académiques, est introduite.
•
1975 La sixième édition de UNIX est produite et devient la première à être commercialisée pour une
somme modique par AT&T.
•
1977 Près de 500 sites utilisent UNIX. Une nouvelle version pour un ordinateur Interdata 8/32 est
produite. Le langage C est aussi amélioré. John Reiser et Tom London, des Laboratoires Bell, écriront
UNIX 32V pour le VAX 11/780. C'est un descendant de cette version qui est actuellement distribué
par l'Université de Berkeley en Californie (UCB).
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
1
/
44
100%