Architecture des ordinateurs

Architecture des ordinateurs
2ème partie
Ordinateurs, Microprocesseurs, Mémoires, langage d'assemblage
Notes de cours
Option : Génie Informatique
DUT/BTS
NGAH ASSE
Institut Universitaire de technologie
Université de Douala
Année 2005
Ce cours a bénéficié de l'appui de la coopération française (Projet Comètes)

Architecture des ordinateurs
Ngah Asse /Génie Informatique/IUT Dla 2005 2/75
Table des matières
Introduction générale...............................................................................................................6
Chapitre 1 ANALYSE MULTICOUCHE DE L’ORDINATEUR...........................7
1.1 Introduction...........................................................................................................7
1.2 Langage et machines virtuelles............................................................................8
1.3 Les machines multicouches Actuelles..................................................................8
1.4 Histoire des machines multicouches..................................................................10
1.5 Matériel et logiciel...............................................................................................10
1.6 Les grandes étapes de l’architecture des ordinateurs......................................10
1.6.1 La génération zéro : les calculateurs mécaniques (1642-1945).......................10
1.6.2 La première génération: les tubes à vide (1945-1955)......................................11
1.6.3 La deuxième génération: les transitors (1955-1965)........................................11
1.6.4 La troisième génération: les circuits intégrés (1965-1980)..............................11
1.6.5 La quatrième génération: les ordinateurs personnels et VLSI (1980-XXXX ).........12
CHAPITRE 2: INTRODUCTION AUX MICROPROCESSEURS.................................14
2.1 Définitions............................................................................................................14
2.2 Fonctionnement du micro-ordinateur : modèle Von Neumann......................14
2.2.1 Rôles des composantes :......................................................................................14
2.2.2 Exécution d’une instruction...............................................................................15
2.2.3 Exécution des programmes.................................................................................16
2.2.4 Architecture et performances.............................................................................16
2.2.4.1 Temps d'exécution...............................................................................................16
2.2.4.2 Amélioration des accès mémoire........................................................................16
2.2.4.3 Modèles d'exécution et réduction du temps d'exécution.................................17
2.3 Structure d’un microprocesseur........................................................................18
2.3.1 Description...........................................................................................................18
2.3.2 Structure interne d'un microprocesseur élémentaire......................................21
2.3.3 Le parallélisme.....................................................................................................24
2.3.4 Le pipelining........................................................................................................25
2.3.5 L'architecture CISC............................................................................................25
2.3.6 L'architecture RISC............................................................................................25
2.3.7 CISC ou RISC......................................................................................................25
2.4 Types de microprocesseurs.................................................................................26
2.5 Historique.............................................................................................................26
2.5.1 Quatre générations informatiques de « minis »................................................26
2.5.2 Historique des microprocesseurs.......................................................................27
2.6 Circuits du micro-ordinateur.............................................................................27
2.6.1 L’horloge à quartz...............................................................................................27
2.6.2 Mesure des performances des microprocesseurs.............................................28
2.6.3 Horloge système...................................................................................................28
2.6.4 Contrôleur de bus................................................................................................29
2.6.5 Horloge calendrier...............................................................................................29
2.6.6 Les mémoires.......................................................................................................29
2.6.6.1 Les mémoires centrales.......................................................................................29
2.6.6.2 Les mémoires de masse.......................................................................................29
CHAPITRE 3: LA MÉMOIRE........................................................................................30
3.1 La mémoire centrale...........................................................................................30

Architecture des ordinateurs
Ngah Asse /Génie Informatique/IUT Dla 2005 3/75
3.1.1 Bit et cellule mémoire..........................................................................................30
3.1.2 Les adresses mémoire..........................................................................................30
3.1.3 Ordonnancement des octets (indianisme).........................................................30
3.1.4 Organisation d’une mémoire..............................................................................30
3.1.4.1 Organisation interne d’une mémoire................................................................30
3.1.4.2 Aspect extérieur des mémoires centrales..........................................................32
3.1.5 Caractéristiques d’une mémoire........................................................................32
3.1.6 Typologie des mémoires......................................................................................32
3.1.6.1 Les mémoires vives..............................................................................................32
3.1.6.2 Les mémoires mortes...........................................................................................32
3.1.7 Relation entre mémoires et microprocesseur...................................................33
3.1.8 Chronogrammes types des mémoires................................................................33
3.1.9 Principe du décodage d’adresse.........................................................................34
3.2 Les mémoires dans les PC...................................................................................35
3.2.1 La barrière des 640 Ko et catégories des mémoires.........................................35
3.2.1.1 La mémoire paginée et les EMM.......................................................................36
3.2.1.2 Les EMS..............................................................................................................36
3.2.1.3 La mémoire étendue............................................................................................36
3.2.1.4 La mémoire haute ou HMA................................................................................37
3.2.2 Adressage des mémoires.....................................................................................37
3.2.2.1 Segmentation de la mémoire..............................................................................37
3.2.2.2 Pagination de la mémoire...................................................................................38
3.2.2.3 Les blocs de mémoire supérieure (UMB)..........................................................38
3.2.3 La mémoire virtuelle...........................................................................................39
3.2.4 Les gestionnaires de mémoire et analyse des mémoires..................................39
3.2.5 La mémoire CMOS.............................................................................................39
3.3 Les modes d'adressage des mémoires................................................................39
3.3.1 Adressage implicite..............................................................................................40
3.3.2 Adressage inhérent ou à registre........................................................................40
3.3.3 Adressage immédiat............................................................................................40
3.3.4 Adressage de registre..........................................................................................40
3.3.5 Adressage direct et absolu..................................................................................40
3.3.6 Adressage indirect par registre..........................................................................41
3.3.7 Adressage indirect par mémoire........................................................................42
3.3.8 Adressage relatif..................................................................................................42
3.3.8.1 Adressage relatif..................................................................................................42
3.3.8.2 Adressage relatif au contenu du compteur ordinal..........................................43
3.3.9 Adressage indexé.................................................................................................43
3.3.10 Adressage par registre de base...........................................................................44
3.3.11 Segmentation de la mémoire..............................................................................44
3.3.11.1 Principe de la segmentation avec les processeurs 16 bits.................................44
3.3.11.2 Protection offerte par les segments....................................................................45
3.3.11.3 Séparation des segments.....................................................................................45
3.3.11.4 Désignation d'une adresse...................................................................................46
3.3.11.5 Contraintes de la segmentation..........................................................................46
3.3.12 Pagination de la mémoire...................................................................................46
3.4 Accès direct en mémoire.....................................................................................47
3.4.1 DMA par halte (arrêt) du processeur................................................................47
3.4.1.1 Organisation d'un échange.................................................................................48
3.4.1.2 Avantages et inconvénients.................................................................................48
3.4.2 DMA par vol de cycle..........................................................................................48
3.4.3 DMA multiplexé..................................................................................................49

Architecture des ordinateurs
Ngah Asse /Génie Informatique/IUT Dla 2005 4/75
3.4.4 Le contrôleur de DMA: 8237..............................................................................49
3.5 La mémoire cache et sa gestion..........................................................................49
3.5.1 Mode de fonctionnement.....................................................................................50
3.5.2 Les niveaux de cache...........................................................................................50
3.5.3 Caches unifiés et caches diversifiés....................................................................50
3.5.4 Cohérence et MESI.............................................................................................51
3.5.5 Architecture des caches.......................................................................................51
3.5.6 Remplacement du contenu de l'antémémoire...................................................53
3.5.7 Mémoire principale et mémoire virtuelle..........................................................53
3.5.8 Hiérarchie des mémoires....................................................................................55
CHAPITRE 4: BUS ET INTERFACES...........................................................................56
4.1 Distribution des interfaces..................................................................................56
4.2 Les bus d’extension du microprocesseur...........................................................57
4.2.1 Le bus ISA............................................................................................................57
4.2.2 Les extensions PCMIA........................................................................................57
4.2.3 Le bus PCI............................................................................................................57
4.2.4 Le bus SCSI (Small Computer System Interface)............................................58
4.2.5 Le bus IDE (Itegrated Drive Electronic)...........................................................58
4.2.6 Arbitrage des bus.................................................................................................58
CHAPITRE 5: INDICATEURS D'ETATS.....................................................................60
5.1 Indicateurs d'états et branchements conditionnels..........................................60
5.2 Etude de quelques indicateurs d'états...............................................................61
5.2.1 Indicateur de zéro................................................................................................61
5.2.2 Indicateur de retenue..........................................................................................61
5.2.3 Indicateur de signe..............................................................................................61
5.2.4 Indicateur de dépassement.................................................................................61
5.2.5 Indicateur de parité.............................................................................................62
5.2.6 Indicateur de demi retenue.................................................................................62
5.2.7 Indicateur d'interruption....................................................................................62
5.2.8 Indicateur de pas à pas ou "Trap"....................................................................62
5.2.9 Indicateur de reprise...........................................................................................62
5.2.10 Indicateur de direction........................................................................................62
Chapitre 6 PROGRAMMATION EN LANGAGE ASSEMBLEUR................................63
6.1 Introduction générale..........................................................................................63
6.2 L'assemblage........................................................................................................64
6.3 Edition de liens.....................................................................................................65
6.4 Chargement du programme...............................................................................65
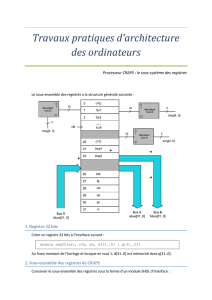
6.5 Les registres.........................................................................................................66
6.5.1 Registres de données...........................................................................................66
6.5.2 Registres d'index..................................................................................................67
6.5.3 Registres de segment...........................................................................................67
6.5.4 Pointeur d'instructions........................................................................................68
6.5.5 Registre Drapeau.................................................................................................69
6.6 Indicateurs d'état.................................................................................................69
6.6.1 Indicateurs de contrôle.......................................................................................69
6.6.2 Signification des principaux indicateurs:..........................................................70
6.6.3 Comparaisons préalables au branchement.......................................................70
6.7 Conditions de branchements..............................................................................71
6.7.1 Premier groupe....................................................................................................71

Architecture des ordinateurs
Ngah Asse /Génie Informatique/IUT Dla 2005 5/75
6.7.2 Deuxième groupe.................................................................................................71
6.7.3 Codage de quelques instructions :.....................................................................71
6.8 Le compteur d'instructions (IP).........................................................................73
6.9 Structure d’un programme assembleur............................................................73
6.10 Déclaration d’un segment...................................................................................74
Bibliographie 75
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
1
/
75
100%