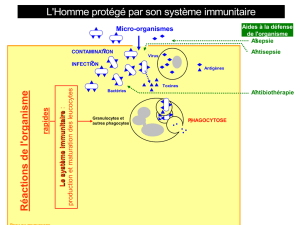
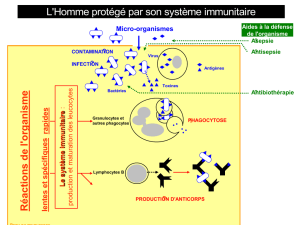
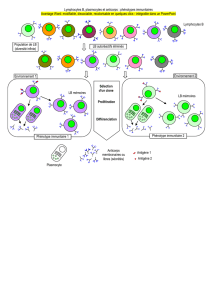
Application des systèmes immunitaires artificiels à la détection d

République Algérienne Démocratique et Populaire
Ministère de l’Enseignement Supérieur et de la Recherche Scientifique
Université des Sciences et de la Technologie d’Oran – Mohamed Boudiaf
USTO-MB
Faculté des Sciences
Département d’Informatique
MEMOIRE
En vue de l’obtention du Diplôme de Magister
Spécialité : Informatique
Option : Modélisation et Simulation (MOSI)
Présenté par : Mr SLIMANI Ahmed
Thème :
Application des systèmes immunitaires
artificiels à la détection d’intrusion
Soutenu devant le jury:
-
Président
Mr. A. BENYETTOU Professeur USTOMB
- Rapporteur Mr. M .BE NYETTOU Professeur USTOMB
-Examinateur Mr. K. BELKADI maitre de conférences USTOMB
-
Examinateur Mr. K. SADOUNI maitre de conférences USTOMB
2010- 2011

Dédicaces
Je dédie ce modeste travail à :
- Mes chers parents qui m’avoir énormément encouragé et soutenu
pendant la réalisation de ce travail, que je ne pourrai assez
remercier de m’avoir apporté le nécessaire.
- Mes chers frères, sœurs et toute la famille de SLIMANI.
- Ma deuxième famille SLIMANI à Oran
- Mes chers frères de la mosquée « el-rachad » cité universitaire C1
- A mes chers amis
- A mes collègues du laboratoire LAMOSI et tous les étudiants
d’université USTO
- Tous ceux qui m’ont aidé de prés ou de loin surtout dans les
moments les plus difficiles.
A tous, je dédie ce modeste travail. ……
Mr. SLIMANI Ahmed.

Remerciements
Tout d’abord je remercie le bon dieu tout puissant qui ma guidé
dans mes pas, qui ma donné le courage, la volonté, et la patience pour
surmonter les épreuves que j’ai rencontré tout au long de ma vie.
Je tiens à exprimer ma sincère gratitude et reconnaissance à mon
encadreur : Mr Mohammed BENYETTOU professeur à l’USTOMB et
responsable de laboratoire LAMOSI pour avoir accepté de diriger ce
travail, pour son aide, sa disponibilité et ses conseils.
Mes remerciements vont aussi à Monsieur Mr Abdelkader
BENYETTOU professeur à l’USTOMB et responsable de l’option
RFIA qui nous a fait l’honneur de présider ce jury.
Je remercie Mr Khaled BELKADI maitre de conférences à
l’USTOMB d’avoir accepté d’examiner ce travail.
Je remercie Mr Kaddour SADOUNI maitre de conférences à
l’USTOMB d’avoir accepté d’examiner ce travail.
Mes remerciements s’adressent à tous mes collègues du
laboratoire LAMOSI.
Enfin je remercie toute personne ayant contribué de prés ou loin à
la réalisation de ce travail.
Mr. Ahmed SLIMANI

Résumé
Face aux nouvelles technologies de l’information et de la communication, apparues avec
l’avènement des réseaux et d’internet, la sécurité informatique est devenue un défi majeur, et les
travaux dans cet axe de recherche sont de plus en plus nombreux.
Divers outils et mécanismes sont développés afin de garantir un niveau de sécurité à la
hauteur des exigences de la vie moderne. Parmi eux, les systèmes de détection d’intrusions destinés à
repérer des activités ou comportements anormaux suspects de nuire au bon fonctionnement du
système.
L’objet de ce mémoire est la conception et la réalisation d’un IDS (Intrusion detection
system) inspiré des systèmes immunitaires naturels. L’étude de systèmes biologiques afin de s’en
inspirer pour la résolution de problèmes informatiques est un axe de l’intelligence artificielle qui a
donné naissance à des méthodes robustes et efficaces (colonies de fourmis, algorithmes génétiques,
réseaux de neurones …etc.). De part leur fonction naturelle, les systèmes immunitaires ont suscité
l’intérêt des chercheurs dans le domaine de la détection d’intrusion, compte tenu des similitudes des
objectifs d’un SIN (système immunitaire naturel) et d’un IDS.
Dans le cadre de ce travail on propose un IDS basé sur le système immunitaire artificiel qui
s’inspire du système immunitaire naturel en utilisant la base de données KDD99. L’algorithme analyse
les connexions réseaux afin de les classer comme normale ou anormales. Les résultats expérimentaux
montrent que le système est performant avec un taux de reconnaissance satisfaisant.
Mots clés : Système de détection d’intrusions, systèmes immunitaires naturels, systèmes
immunitaires artificiels, KDD99.
Abstract
In view of new communication and information technologies that appeared with the
emergence of networks and Internet, the computer security became a major challenge, and
works in this research axis are increasingly numerous.
Various tools and mechanisms are developed in order to guarantee a safety level up to the
requirements of modern life. Among them, intrusion detection systems (IDS) intended to locate
activities or abnormal behaviors suspect to be detrimental to the correct operation of the system.
The purpose of this work is the design and the realization of an IDS inspired from
natural immune systems. The study of biological systems to get inspired from them for the
resolution of computer science problems is an axis of the artificial intelligence field which gave
rise to robust and effective methods (ants colonies, genetic algorithms, neuron networks… etc)
Within the framework of this work one proposes IDS based on the artificial immune system
which takes as a starting point the natural immune system by using the base of data KDD99. The
algorithm analyzes connections networks in order to classify them like normal or abnormal. The
experimental results show that the system is powerful with a satisfying rate of recognition.
Key words: intrusions detection System, natural immune system, artificial immune systems,
KDD99.

Sommaire
Introduction général .......................................................................................................................................... 1
Chapitre 01 : Introduction à la sécurité informatique .............................................................................. 3
1- La sécurité informatique ........................................................................................................................... 4
2- Services et mécanismes de sécurité .......................................................................................................... 5
2.1. Les services de sécurité ..................................................................................................................... 5
2.2. Les mécanismes de sécurité
............................................................................................................. 6
3-
Services et mécanismes de sécurité .......................................................................................................... 8
3.1 Types d’attaques .................................................................................................................................. 9
3.2 Profils et capacités des attaquants ...................................................................................................... 9
4- Quelques possibilités en matière de sécurité réseaux
......................................................................... 10
4.1 Les Firewalls
.................................................................................................................................
10
4.2 Les filtres de paquets
....................................................................................................................
11
4.3 Les scanners et les outils relatifs à la sécurité
.............................................................................
11
4.4 Les systèmes de détection d’intrusions
........................................................................................
12
5- Conclusion
..........................................................................................................................................
12
Chapitre 02 : Détection d’intrusion ............................................................................................................. 13
1- Introduction ............................................................................................................................................ 14
2- Intrusions informatiques ......................................................................................................................... 14
2.1 Types de pirates informatique ......................................................................................................... 15
2.2 Différentes phases d’une attaque ..................................................................................................... 15
2.3 contre- mesures .................................................................................................................................. 18
3- Systèmes de détection d’intrusions ........................................................................................................ 18
3.1 Introduction ...................................................................................................................................... 18
3.1.1 C’est Quoi la détection d’intrusion ? ................................................................................... 18
3.1.2 Efficacité des systèmes de détection d’intrusion .......................................................... 20
3.1.3 Que doit assurer la détection d'intrusion ? ........................................................................ 20
3.2 Modèle de processus de la détection d’intrusion ......................................................................... 21
4- Classification
des systèmes de détection d'intrusion ........................................................................... 22
4.1 La méthode de détection .................................................................................................................. 23
4.1.1 L’approche comportementale ............................................................................................. 23
4.1.2 L’approche basée connaissance .......................................................................................... 23
4.2 Le comportement après la détection d’intrusions ......................................................................... 23
4.2.1 Réponse active ........................................................................................................................ 23
4.2.2 Réponse passive ..................................................................................................................... 23
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
1
/
129
100%