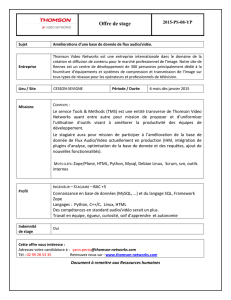
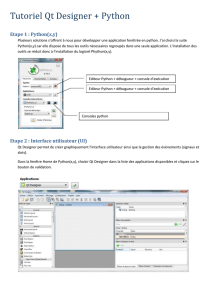
PDF FR


2

Table des mati`eres
Introduction iii
1 Comprendre les interfaces 1
2 Ecrire des tests unitaires pour Python 7
3´
Ecrire des tests fonctionnels 13
4 Comprendre les adapters 19
5 Comprendre les ´ev`enements 23
6´
Ecrire du reSTructuredText pour la documentation et les doc-
tests 27
7 Trouver le bon rythme entre codage, documentation, tests fonc-
tionnels et unitaires 31
8 Enregistrer une session utilisateur pour les tests 35
9 Organiser le code dans un paquet 39
10 Cr´e´er un flux RSS pour tous les conteneurs 45
11 R´ecup´erer l’URL d’un objet 51
12 Mettre en place une file asynchrone d’envoi de mails 53
i

ii TABLE DES MATI `
ERES

Introduction
Ce livre contient des recettes pour Zope 3.2.1, issues du projet zope-cookbook.org.
Zope 3 continue son ´evolution mais la majorit´e de ces recettes restent d’actua-
lit´e.
Ce livre a ´et´e ´ecrit par Tarek Ziad´e et est distribu´e en licence C-C Attribution-
NonCommercial-NoDerivs 2.5
http ://creativecommons.org/licenses/by-nc-nd/2.5/
iii
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
1
/
62
100%