Les réseaux

© Groupe Eyrolles, 2012
16
Les réseaux
CHAPITRE AVANCÉ
Vinton Cerf (1943-) et Robert Kahn
(1938-) ont inventé, au début des
années 1970, le protocole de trans-
mission de paquets de données IP
(Internet Protocol) et le protocole de
contrôle de flux de données TCP
(Transmission Control Protocol). Il
s’agit des deux principaux protocoles
du réseau Internet. Ils donnent à ce
réseau sa fiabilité, sa robustesse en
cas de pannes ou de modifications et
sa capacité à évoluer. Cela a valu à
leurs auteurs le surnom de « pères
d’Internet. »
Les ordinateurs parlent aux ordinateurs.
Dans ce chapitre, nous voyons comment les ordinateurs
communiquent entre eux, et comment ces communications
se composent pour faire fonctionner le réseau Internet.
Ces mécanismes de communication de machine à machine
s’appellent des protocoles.
Les protocoles de la couche physique connectent les bus
des ordinateurs. Les protocoles de la couche lien organisent
un réseau local autour d’un serveur et repèrent les ordinateurs
par l’adresse MAC de leur carte réseau. Les protocoles
de la couche réseau organisent les réseaux locaux de proche
en proche et repèrent les ordinateurs par leur adresse IP.
Nous expliquons comment les informations sont acheminées
au travers du réseau à l’aide de routeurs.
ManuelDowek.book Page 197 Monday, July 9, 2012 4:58 PM

Troisième partie – Machines
© Groupe Eyrolles, 2012
198
Nous avons vu qu’un ordinateur pouvait se décrire à différentes échelles :
les transistors s’assemblent en portes booléennes, qui s’assemblent à leur
tour en composants – processeurs, mémoires, etc. – qui s’assemblent à
leur tour en ordinateurs. Et nous pouvons continuer, car les ordinateurs
s’assemblent à leur tour en réseaux de différentes tailles : des réseaux les
plus simples, formés de deux ordinateurs reliés par un câble ou par radio,
aux réseaux locaux connectant quelques ordinateurs entre eux – les ordi-
nateurs d’un lycée par exemple –, qui s’assemblent à leur tour pour
former le plus grand des réseaux : Internet, lequel relie presque tous les
ordinateurs du monde.
Les protocoles
Si un programme PA, par exemple un logiciel de courrier électronique, exé-
cuté sur un ordinateur A, veut communiquer des informations à un autre
programme PB, exécuté sur un ordinateur B, il sous-traite cette tâche à un
programme spécialisé QA, exécuté sur l’ordinateur A, qui met en œuvre un
protocole. Ce programme QA dialogue, suivant les spécifications de ce pro-
tocole, avec un programme homologue QB exécuté sur l’ordinateur B, ce
qui permet ainsi la communication entre les programmes PA et PB.
En fait, le programme QA sous-traite, à son tour, certaines tâches moins
sophistiquées à d’autres programmes mettant en œuvre d’autres protocoles,
qui sous-traitent, de même, certaines tâches encore plus élémentaires à
d’autres protocoles, etc. On peut ainsi classer les protocoles en couches hié-
rarchiques, par le niveau de sophistication des tâches qu’ils exécutent.
Ainsi, les informations envoyées par le programme de courrier électro-
nique sont d’abord confiées à un protocole de la couche application, qui
les confie à un protocole de la couche transport, qui les confie à un pro-
tocole de la couche réseau, qui les confie à un protocole de la couche
lien, qui les confie à un protocole de la couche physique, qui les transmet
effectivement vers l’ordinateur B.
Quand on confie une lettre à un facteur, on doit la mettre dans une enve-
loppe et ajouter sur l’enveloppe des informations supplémentaires :
l’adresse du destinataire, sa propre adresse, une preuve de paiement, etc.
De même, quand un protocole de la couche k+1 confie des informations
à un protocole de la couche k, celui-ci ajoute à ces informations un en-
tête Hk qui contient des informations, comme l’adresse de l’ordinateur
destinataire, utilisées par le protocole de la couche k. On appelle cela
l’encapsulation des informations. Quand les informations I confiées par la
T
Réseau
Un
réseau
est un ensemble d’ordinateurs et de
connexions qui permettent à chaque ordinateur de
communiquer avec tous les autres, éventuellement
en passant par des intermédiaires.
T
Protocole
Un
protocole
est un ensemble de règles qui
régissent la transmission d’informations sur un
réseau. Il existe de nombreux protocoles, chacun
spécialisé dans une tâche bien précise.
T
Couche
Une
couche
est un ensemble de protocoles qui
effectuent des tâches de même niveau. On dis-
tingue cinq couches appelées
couche applica-
tion
,
couche transport
,
couche réseau
,
couche lien
et
couche physique
.
ManuelDowek.book Page 198 Monday, July 9, 2012 4:58 PM

16 – Les réseaux
© Groupe Eyrolles, 2012 199
couche application à la couche transport arrivent à un protocole de la
couche physique, plusieurs en-têtes H4, H3, H2, H1 leur ont été ajoutés.
Ces en-têtes sont supprimés à la réception : la couche k analyse puis
supprime Hk avant de passer l’information à la couche k+1. On appelle
cela la décapsulation des informations.
Système en couches,
piles de protocoles. Encapsulation
et décapsulation de l’information.
A
LLER
PLUS
LOIN
Les normes
Des
normes
régissent les rôles de chaque couche, leurs interactions et les
spécifications de chaque protocole. Ces normes permettent au réseau
Internet de fonctionner à l’échelle mondiale et assurent la modularité du
système : il est possible de modifier les protocoles à l’œuvre au sein d’une
couche, sans modifier les protocoles des autres couches, et le système con-
tinue à fonctionner dans son ensemble. Cette modularité est analogue au
fait de pouvoir changer un composant matériel d’un ordinateur, par
exemple sa carte graphique, sans devoir rien changer d’autre. Cette
modularité est essentielle pour permettre au système d’évoluer.
ManuelDowek.book Page 199 Monday, July 9, 2012 4:58 PM

Troisième partie – Machines
© Groupe Eyrolles, 2012
200
La communication bit par bit :
les protocoles de la couche physique
Commençons la présentation de ces protocoles par ceux de la couche
physique. Un protocole de la couche physique doit réaliser une tâche
extrêmement simple : communiquer des bits entre deux ordinateurs
reliés par un câble ou par radio.
Pour relier deux ordinateurs par un câble, et donc réaliser le réseau le
plus simple qui soit, on pourrait prolonger le bus de l’un des ordinateurs,
afin de le connecter au bus de l’autre. Ainsi, le processeur du premier
ordinateur pourrait écrire, avec l’instruction STA, non seulement dans sa
propre mémoire, mais aussi dans celle du second. Le processeur du
second ordinateur pourrait alors charger, avec l’instruction LDA, la
valeur écrite par celui du premier.
La technique utilisée en réalité n’est pas beaucoup plus compliquée : le
processeur du premier ordinateur envoie des informations par le bus vers
l’un de ses périphériques, la carte réseau, qui les transmet par un câble – ou
par un autre support physique, par exemple par radio – à la carte réseau du
second ordinateur qui les transmet, par le bus, à son processeur.
La transmission d’une carte réseau à l’autre met en œuvre un protocole,
appelé protocole physique. Un exemple de protocole physique est la com-
munication par codes-barres à deux dimensions, comme les picto-
grammes Flashcode utilisés par les téléphones, où chaque bit est exprimé
par un carré noir ou blanc.
Transmission point à point
Flashcode exprimant le nombre
5412082001000261
ManuelDowek.book Page 200 Monday, July 9, 2012 4:58 PM

16 – Les réseaux
© Groupe Eyrolles, 2012 201
Les protocoles physiques qui permettent à deux ordinateurs de commu-
niquer par câble ou par radio ne sont pas très différents. Cependant, au
lieu d’utiliser des carrés noirs et blancs, ils représentent les informations
par des signaux électromagnétiques, par exemple des variations de lon-
gueur d’onde, de phase ou d’intensité d’une onde.
Exercice 16.1
On utilise un lien physique peu fiable : à chaque fois que l’on transmet un 0 ou
un 1, la probabilité que ce bit ne soit pas reconnaissable à l’arrivée est 3/10.
Pour pallier ce manque de fiabilité, on utilise une forme de redondance (voir
le chapitre 12) : quand l’ordinateur émetteur demande à sa carte réseau
d’envoyer un 0, cette dernière envoie la suite de bits 0, 1, 0, 0, 1, qui est inter-
prétée par la carte réseau de l’ordinateur récepteur comme un 0. De même,
quand l’ordinateur émetteur demande à sa carte réseau d’envoyer un 1, elle
envoie la suite de bits 1, 0, 1, 1, 0 qui est interprétée par la carte réseau de
l’ordinateur récepteur comme un 1.
À partir de combien de bits erronés la suite de cinq bits envoyée n’est-elle
plus discernable de l’autre suite ?
En déduire la probabilité qu’une suite de cinq bits envoyée ne soit pas
reconnaissable à l’arrivée.
Quels sont les avantages et inconvénients de cette méthode ?
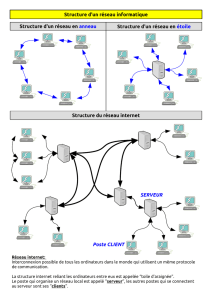
Les réseaux locaux :
les protocoles de la couche lien
L’étape suivante consiste à construire un réseau local, c’est-à-dire formé
de quelques machines connectées, par un protocole physique, à un ordi-
nateur central : un serveur. Pour envoyer des informations à un autre
ordinateur, chaque ordinateur passe par le serveur.
De même qu’il était nécessaire de distinguer les différentes cases de la
mémoire d’un ordinateur en donnant à chacune un nom, son adresse, il
est nécessaire de distinguer les différents ordinateurs d’un réseau local en
donnant à chacun un nom : son adresse MAC (Medium Access Control).
Une adresse MAC est un mot de 48 bits que l’on écrit comme un sextu-
plet de nombres de deux chiffres en base seize, les seize chiffres s’écri-
vant 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, a, b, c, d, e, f : par exemple
10:93:e9:0a:42:ac. Une adresse MAC unique est attribuée à chaque carte
réseau au moment de sa fabrication. L’adresse MAC d’une carte réseau,
périphérique d’un ordinateur, identifie ce dernier sur le réseau local.
S
UJET
D
’
EXPOSÉ
Protocoles et codages
Chercher sur le Web quels sont les protocoles
utilisés dans les liaisons RS-232 d’une part, et
dans les liaisons USB d’autre part. Quels sont les
avantages d’USB par rapport à RS-232 ? Cher-
cher de même ce que sont les codages Man-
chester d’une part et NRZI d’autre part. Quels
sont les avantages du codage Manchester par
rapport au codage NRZI ?
ManuelDowek.book Page 201 Monday, July 9, 2012 4:58 PM
 6
7
8
9
10
11
12
13
14
15
16
17
18
6
7
8
9
10
11
12
13
14
15
16
17
18
1
/
18
100%