Dans le JDK 1

Lodomez Olivier 05/11/2002
Résumé JBuilder
1
Dans le JDK 1.02 l’accès à une base distante était impossible à réaliser depuis une applet.
Dans le JDK 1.1 le but à été de normaliser une couche d’accès aux données. Celle-ci est
connue sous le nom de JDBC (Java DataBase Connectivity)
Ensuite, la norme JDBC 2.0 est apparue, elle apporte un support partiel de SQL3
L’API d’accès aux données de Java : JDBC
JavaSoft a créé cet ensemble de classes et de méthodes (API) en reprenant les spécifications
de Microsoft ODBC.
ODBC est une interface de programmation définie par Microsoft qui permet à des
applications d’accéder à des données à l’aide d’un ensemble de fonctions spécifiques.
Il est ainsi possible de se connecter à des bases de données distante, d’exécuter des requêtes
SQL... des procédures stockées, d’accéder aux métadonnées, … et ce, quel que soit le format
du SGBD.
Les bases Oracle, Informix, InterBase … peuvent ainsi être utilisées par le biais de cette
technique. Il faut pour cela « passer » par ce qu’il est convenu d’appeler un driver. C’est lui
qui va transmettre les ordres et commandes provenant de l’application ou l’applet Java, au
serveur concerné. Si besoin est, une opération de conversion est effectuée afin de traduire les
commandes dans un format compréhensible pat le server.
Puisqu’un driver ODBC doit être stocké sur le poste d’exécution, une applet exécutée depuis
un serveur ne peut jamais utiliser de drivers de type I (passerelle JDBC-ODBC). Rappelons
qu’une applet ne peut pas, pour des raisons de sécurité, accéder au système de fichiers du
poste d’exécution si elle a été chargée à partir d’un serveur distant.
Les composants de la palette DataExpress
La réalisation de votre application base de données va probablement passer par l’utilisation
des composants de la palette dénommée DataExpress. Ces composants prendront non
seulement en charge la gestion du driver JDBC, mais mettrons aussi à votre disposition des
classes de plus haut niveau chargées de vous faciliter la tâche.
DataExpress : dénomination commune pour un ensemble de classes et de composants qui
permettent l’accès aux diverses fonctionnalités base de données définies dans JDBC.
Entièrement écrits en Java, ils sont portables d’un environnement à un autre ; Leur principal
intérêt est de masquer la complexité du développement JDBC. Ils permettent le codage de
l’accès aux données de manière visuelle, en générant pour vous le code requis par les drivers
utilisé. Par ailleurs, définis à un niveau supérieur à JDBC, ils ne sont pas liés à un format de
données.

Lodomez Olivier 05/11/2002
Résumé JBuilder
2
- DataBase -> Connexion à l base de données via un driver
- TableDataSet -> Composant générique ne comprenant pas de mécanisme
d’accès aux données. C’est en fait une coquille vide sur laquelle s’appuient les
autres composants d’accès aux données. (souvent utilisé en conjonction avec
un TextDataFile)
- TextDataFile -> Destiné à manipuler des fichiers texte, ce composant sert aux
opérations d’importation et d’exportation de données.
- QueryDataSet -> Composant destinés à la gestion et à l’exécution des requêtes
SQL. Il est à remarquer que c’est le seul composant disponible pour accéder à
une table
- …
Schéma d’ensemble de l’accès aux données
1. Se connecter à la base de données avec le composant DataBase
2. Exécuter une requête SQL pour accéder à la source de données (QueryDataSet)
3. Visualiser les données via les composants de la JBCL ou dbSwing
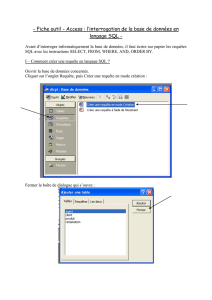
Etape 1 : Se connecter à la Base de Données [Le composant DataBase]
La connexion à la base est la première étape à mettre en œuvre pour développer une
application ou une applet avec des bases de données
La connexion est toujours réalisée par l’intermédiaire d’un composant DataBase. La première
opération à réaliser est de placer un composant de ce type dabs la ficher qui va contenir els
données. Comme tous les composants de la palette DataExpress Ce composant est de type non
visuel : il n’apparaîtra pas dans la fiche. Il vous faudra le sélectionner dans l’arbre des
composants du navigateur d’applications.
Pour définir la connexion à la base de données, il faut positionner la propriété connexion de ce
composant.
accéder à la base de données besoin de renseigner des paramètres

Lodomez Olivier 05/11/2002
Résumé JBuilder
3
Driver : toute connexion s’effectue par le biais d’un driver
Connexion URL : la base à laquelle vous allez vous connecter est toujours identifiée par une
URL
Nom d’utilisateur : Lorsque vous demandez une connexion à un serveur de bases de
données, il faut vous identifié afin de vérifier si vous avez le droit d’accéder aux données. Il
détermine aussi les règles d’accès qui vous concernent : lecture, lecture et écriture, restrictions
diverses … Ce champ contient le nom qui sera transmis au serveur à l’initialisation de la
connexion afin de vous identifier.
Mot de passe : En association avec el nom d’utilisateur, une connexion sur un serveur
nécessite un mot de passe afin de déterminer vos droits d’accès à la base de données.
Le tandem InterClient / InterServer
Borland a implémenté l’accès direct à InterBase sous la forme d’un driver de type III
Celui-ci se compose de deux modules
InterClient : Situé sur le poste client, c’est un ensemble de classes écrites en Java destinées à
prendre en charge le dialogue entre l’application (ou l’applet) et InterServer
InterServer : Cet outil joue le rôle d’interface entre les appels JDBC de l’application qui lui
sont transmis par InterClient et les appels natifs à la base de données. Cette base peut être
indifféremment locale ou distante.
InterClient : implémente la quasi-totalité de la norme JDBC ainsi qu’un ensemble de points
spécifiques à InterBase : cela afin de garantir des performances optimales.
L’accès à InterBase via InterClient permet à une applet d’accéder à une base de données sans
pour cela se préoccuper du système d’exploitation ni de la configuration du poste d’exécution.

Lodomez Olivier 05/11/2002
Résumé JBuilder
4
En effet une solution 100 % Java permet de garantir la portabilité d votre code et de faciliter
la phase de déploiement.
Dans ce cas, rien ne doit être préinstallé sur le poste client, ce qui permet d’affirmer la
supériorité de cette solution par rapport à l’utilisation de drivers de type I ou II
InterServer : Son rôle est de convertir tous les appels d’InterClient en commande
directement compréhensible par InterBase. C’est en fait un processus qui s’exécute sur
l’ordinateur qui contient la base de données. Dans le cas d’une applet, il s’agit très souvent du
Serveur Web.
Principe de fonctionnement
1. L’utilisateur requiert le chargement d’une page HTML
2. Cette page lui est expédiée vers le protocole http
3. Une applet référencée dans la page est transférée sur son poste
4. le code de l’applet s’exécute sur le poste de l’utilisateur, et la référence au driver
InterClient provoque son transfert à partir de ce même serveur Web.
5. InterClient s’exécute à partir de l’applet et établit un dialogue avec InterServer, situé
sur le serveur Web
6. InterServer, à son tour va se connecter à la base de données InterBase et demander
l’exécution d’une requête SQL
7. l’ensemble de données résultant est transmis au poste client par l’intermédiaire
d’InterServer et d’InterClient.
8. le programme s’exécute et l’utilisateur manipule les données présentées.
9. Lors du déchargement de l’applet, le driver InterClient est supprimé du poste client.
Etape 2 : Exécuter une requête de sélection pour obtenir une source de données [Le
composant QueryDataSet]
Moyen indispensable pour accéder à des informations, une requête est une commande , un
ordre envoyé à un serveur afin d’obtenir des informations. Ces demandes sont exprimées
dans un langage universel compréhensible quel que soit le serveur utilisé, c’est-à-dire en
SQL.
A partir de JBuilder, il existe deux techniques différentes pour exécuter une requête
- utiliser directement les classes de JDBC
- Par le biais des composants du DataExpress utilisés sous la forme de ligne de
codes Java ou visuellement depuis le concepteur graphique d’interface.
Avec JBuilder il est impossible de visualiser une table sans passer par l’exécution d’une
requête.
Présentation du composant QueryDataSet
Le composant QueryDataSet est l’un des constituants essentiels du Borland DataExpress. Il a
pour but d’exécuter une requête sur un serveur ;

Lodomez Olivier 05/11/2002
Résumé JBuilder
5
- transmission d’une requête SQL à un serveur de base de données
- récupération des données résultantes et mise à disposition de ces données pour
les autres composants du DataExpress.
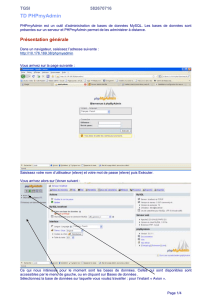
La boîte de saisie de requêtes
Cette boîte constitue le principal outil d’aide à la saisie de requêtes du DataExpress.
Une fois la requête définie, il est préférable de la valider en essayant de l’exécuter.
Etape 3 : Visualiser les données
Les quatre bibliothèques de classes disponibles pour visualiser des données sont :
- AWT
- Swing
- dbSwing
- JBCL
Les composants WAT
Les composants de la palette WAT sont très intéressants dans le cadre du développement
d’une applet Java, car ils offrent un avantage unique : basée sur le JDK 1.02, les applets sont
toujours correctement exécutées par le navigateur, indépendamment de sa version .
L’unique avantage de l’utilisation d’AWT dans le cadre d’un développement base de données
est d’alléger la phase de déploiement. Effectivement, aucune bibliothèque particulière ne doit
être déployée sur le poste d’exécution puisque tous les composants WAT sont intégrés à la
machine virtuelle.
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
6
7
8
9
10
11
12
13
14
15
16
17
18
19
1
/
19
100%