Fonctionnalités internationales dans Microsoft

Fonctionnalités internationales dans Microsoft SQL Server 2005
Formation des utilisateurs SQL Server
Microsoft Corporation
Février 2007
S'applique à :
Microsoft SQL Server 2005
Unicode
Résumé : Ce livre blanc présente aux développeurs Microsoft SQL Server les fonctionnalités
internationales de Microsoft SQL Server 2005. Il propose notamment une explication du
format Unicode et aborde l'ajout de la prise en charge de caractères supplémentaires dans
SQL Server 2005, les modifications du classement dans les différentes versions de
SQL Server, les modifications des types de données, les performances, les mises à jour pour
les fournisseurs de données et les nouvelles fonctionnalités de prise en charge internationales
dans SQL Server 2005 Analysis Services et SQL Server 2005 Integration Services. (75 pages
imprimées)
Sommaire
Introduction
Prise en charge du format Unicode dans SQL Server 2005
Types de données dans SQL Server 2005
Performances et espace de stockage
Migration des informations de métadonnées dans les tables système
Classements
Communications serveur-clients (technologies d'accès aux données)
Données multilingues dans l'interface utilisateur
Transact-SQL en multilingue
Prise en charge des paramètres régionaux dans SQL Server 2005
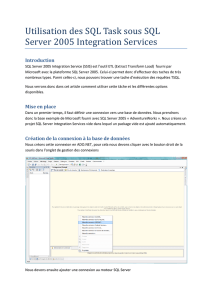
SQL Server 2005 Integration Services
Utilisation des utilitaires de ligne de commande avec les données multilingues
Fonctionnalités internationales dans SQL Server Analysis Services
Prise en charge du format XML dans SQL Server 2005
Améliorations apportées à la recherche de texte intégral
Interaction avec les autres produits de base de données
Conclusion
Remerciements
Annexe A : Suffixes de classement
Annexe B : Paramètres régionaux pris en charge dans Windows
Annexe C : Ordres de tri spécifiques à SQL
Annexe D : Langues prises en charge dans SQL Server 2005
Annexe E : Langues en texte intégral ajoutées dans SQL Server 2005
Annexe F : Classements mis à jour dans SQL Server 2005

Introduction
Microsoft SQL Server 2005 s'appuie sur la prise en charge d'Unicode et de XML introduite
dans SQL Server 2000 et y ajoute une nouvelle série puissante d'outils de développement et
de requête grâce à SQL Server Management Studio et Business Intelligence Development
Studio. Des fonctionnalités multilingues robustes font de SQL Server 2005 un produit de base
de données et une plate-forme d'applications attrayants pour la prise en charge des opérations
et des environnements au niveau international.
Ce livre blanc offre une vue d'ensemble de ces fonctionnalités dans un contexte global. Il
répertorie les fonctionnalités liées aux exigences des activités internationales et multilingues
et explique comment les décisions de conception peuvent affecter de nombreux aspects d'un
projet.
Remarque : Ce document utilise les polices internationales suivantes pour offrir des
exemples de certains caractères internationaux : Arial Unicode MS, Latha, Mangal,
PmingLiu, Gulim, SimSun et MS-Mincho. Le fait de ne pas avoir ces polices installées
n'affectera pas sérieusement l'applicabilité de ce document.
Unicode Support in SQL Server 2005
La prise en charge des caractères Unicode constitue la base de la prise en charge multilingue
dans SQL Server 2005.
Unicode est une norme créée par le Consortium Unicode, une organisation qui vise à instaurer
un jeu de caractères unique pour toutes les langues. SQL Server 2005 prend en charge la
norme Unicode version 3.2. La version 3.01 de la norme Unicode est identique à ISO-10646,
une norme internationale qui correspond à tous les points de code dans Unicode.
Unicode fournit un point de code unique pour chaque caractère, quels que soient la plate-
forme, le programme ou la langue. Un programme qui prend en charge Unicode peut gérer
des données dans n'importe quelle langue. Parce qu'il est conçu pour couvrir tous les
caractères de toutes les langues au monde, il n'est pas nécessaire d'utiliser des pages de code
différentes pour gérer différents jeux de caractères.
Dans la mesure où tous les systèmes Unicode utilisent de façon cohérente les mêmes schémas
de bits pour représenter tous les caractères, il existe aucun problème de conversion incorrecte
des caractères en cas de transfert d'un système à un autre.
La façon la plus simple de gérer les données de caractère dans les bases de données
internationales est toujours d'utiliser les types de données Unicode nchar, nvarchar et
nvarchar(max) plutôt que leurs équivalents non Unicode : char, varchar et text. Ainsi, les
clients voient les mêmes caractères dans les données que tous les autres clients. Si toutes les
applications qui utilisent des bases de données internationales exploitent également des
variables Unicode au lieu de variables non Unicode, il n'est pas nécessaire d'exécuter des
conversions de caractères dans le système.
Remarque : Le type de données ntext sera supprimé dans une future version de
Microsoft SQL Server.

Les points de code Unicode et les caractères qu'ils représentent sont séparés du glyphe utilisé
pour le rendu visuel. Un glyphe est défini par la norme ISO (ISO/CEI 9541-1) comme « un
symbole graphique, abstrait et reconnaissable qui est indépendant d'une conception
spécifique ». Donc, un caractère n'est pas nécessairement toujours représenté par le même
glyphe, ou même un glyphe unique. La police que vous choisissez détermine le glyphe qui
sera utilisé pour représenter un point de code ou une série de points de code particuliers.
Pour plus d'informations, consultez le site Web du consortium Unicode.
Codages
Unicode mappe des points de code sur les caractères, mais il ne spécifie pas comment les
données seront représentées dans la mémoire, dans une base de données ou sur une page Web.
C'est là que le codage des données Unicode entre en jeu. Il existe de nombreux de codages
différents pour Unicode. La plupart du temps, vous pouvez simplement choisir un type de
données Unicode sans vous soucier de ces détails. Toutefois, il est important de connaître le
codage lorsque vous êtes dans les situations suivantes :
dans le cas d'une application qui peut coder Unicode différemment ;
lors de l'envoi de données à d'autres plates-formes (autres que Microsoft Windows) ou
des serveurs Web ;
lors de l'importation de données depuis ou l'exportation de données vers d'autres
codages.
La norme Unicode définit plusieurs codages de son jeu de caractères unique : UTF-7, UTF-8,
UTF-16 et UTF-32. Cette section décrit ces codages courants :
UCS-2
UTF-16
UTF-8
Généralement, SQL Server stocke Unicode dans le schéma de codage UCS-2. Cependant, de
nombreux clients traitent Unicode dans un autre schéma de codage, tel qu'UTF-8. Ce scénario
est courant dans les applications Web. Dans les applications Microsoft Visual Basic, les
chaînes de caractères sont traitées dans le schéma de code UCS-2. Vous n'avez donc pas
besoin de spécifier explicitement les conversions de schéma de codage entre les applications
Visual Basic et une instance de SQL Server.
SQL Server 2005 code les données XML en utilisant Unicode (UTF-16). Les données d'une
colonne de type xml sont enregistrées dans un format interne sous forme de gros objets
binaires (BLOB) afin de prendre en charge les caractéristiques du modèle XML, telles que
l'ordre des documents et les structures récurrentes. C'est pourquoi les données XML
récupérées du serveur sortent en UTF-16. Si vous souhaitez un codage différent pour la
récupération de données, votre application doit exécuter la conversion nécessaire sur les
données UTF-16 récupérées. Les pratiques XML recommandées dans les Livres
SQL Server 2005 en ligne fournissent un exemple du mode de déclaration explicite d'un
codage pour les données XML récupérées d'une colonne varchar(max).
Le codage UTF-16 est utilisé parce qu'il peut gérer des caractères de 2 ou 4 octets et est traité
selon un protocole orienté octets. Ces qualités font d'UTF-16 un schéma de codage

particulièrement bien adapté pour traverser différents ordinateurs utilisant des codages et des
systèmes d'ordonnancement d'octet différents. Dans la mesure où les données XML sont
généralement largement partagées sur les réseaux, il est judicieux de maintenir le stockage
UTF-16 par défaut des données XML dans votre base de données et lorsque vous exportez les
données XML vers les clients.
UCS-2
UCS-2 est un prédécesseur d'UTF-16. UCS-2 diffère d’UTF-16 dans le sens où UCS-2 est un
codage de longueur fixe qui représente tous les caractères sous forme de valeur 16 bits
(2 octets) et ne prend donc pas en charge de caractères supplémentaires. UCS-2 est
fréquemment confondu avec UTF-16, qui est utilisé en interne pour représenter le texte dans
les systèmes d'exploitation Microsoft Windows (Windows NT, Windows 2000, Windows XP
et Windows CE), mais UCS-2 est plus limité.
Remarque : Pour obtenir les toutes dernières informations sur l'utilisation d'Unicode dans le
système d'exploitation Windows, consultez la rubrique Unicode dans la bibliothèque MSDN
(Microsoft Developer Network). Il est recommandé qu'une application Windows utilise UTF-
16 en interne et ne soit converti dans le cadre d'une « thin layer » via l'interface que si un autre
format doit être utilisé.
Les informations enregistrées en Unicode dans Microsoft SQL Server 2000 et
Microsoft SQL Server 2005 utilisent le codage UCS-2, qui enregistre chaque caractère sous la
forme de deux octets, quel que soit le caractère utilisé. Ainsi, la lettre latine « A » est traitée
de la même façon que le caractère cyrillique Sha ()), le caractère hébraïque Lamed (ì), le
caractère tamoul Rra (?) ou le caractère japonais Hiragana E (‚¦). Chacun possède un point de
code unique (pour ces lettres, les points de code sont U+0041, U+0248, U+05DC, U+0BB1 et
U+3048 respectivement, où chaque nombre hexadécimal à quatre chiffres représente les deux
octets utilisés par UCS-2).
Dans la mesure où UCS-2 n'autorise que 65 536 points de code différents pour le codage, il ne
gère pas en natif les caractères supplémentaires. Il traite plutôt les caractères supplémentaires
comme une paire de caractères Unicode de substitution non définis qui, lorsqu'ils sont
appariés, définissent un caractère supplémentaire. Cependant, SQL Server peut enregistrer des
caractères supplémentaires sans risque de perte ou d'altération. Vous pouvez étendre les
fonctionnalités de SQL Server pour utiliser les paires de substitution en créant des fonctions
CLR personnalisées. Pour plus d'informations sur l'utilisation des paires de substitution et des
caractères supplémentaires, reportez-vous à la section « Caractères supplémentaires et paires
de substitution », plus loin dans ce livre blanc.
Remarque : Les caractères supplémentaires se définissent comme étant « un caractère codé
en Unicode possédant un point de code supplémentaire ». Les points de code supplémentaires
se trouvent dans la plage entre U+10000 et U+10FFFF.
UTF-8
UTF-8 est un schéma de codage conçu pour traiter les données Unicode indépendamment de
l'ordonnancement des octets sur l'ordinateur. UTF-8 est utile pour travailler avec ASCII et
d'autres systèmes orientés sur les octets qui nécessitent des codages de 8 bits, tels que les
serveurs de messagerie qui doivent couvrir un vaste groupe d'ordinateurs utilisant des codages

différents, des ordres d'octet différents et des langues différentes. Bien que SQL Server 2005
n'enregistre pas de données au format UTF-8, il prend en charge UTF-8 pour traiter les
données XML (Extensible Markup Language). Pour plus d'informations, consultez la section
Prise en charge du format XML dans SQL Server 2005 de ce document.
D'autres systèmes de base de données, tels qu'Oracle et Sybase SQL Server, prennent en
charge Unicode en utilisant le stockage UTF-8. En fonction de l'implémentation d'un serveur,
cela peut être techniquement plus facile à mettre en œuvre pour un moteur de base de
données, parce que le code de gestion de texte existant sur le serveur ne nécessite pas de
modifications majeures pour traiter les données octet par octet. Cependant, dans
l'environnement Windows, le stockage UTF-8 présente plusieurs inconvénients :
Le modèle COM (Component Object Model) prend uniquement en charge UTF-
16/UCS-2 dans ses API et interfaces. Donc, si des données sont enregistrées au format
UTF-8, une conversion constante est nécessaire. Ce problème n'apparaît qu'avec
l'utilisation de COM. Le moteur de base de données SQL Server n'appelle
généralement pas les interfaces COM.
Les noyaux de Windows XP et Windows Server 2003 sont tous les deux en Unicode.
UTF-16 est le codage standard pour Windows 2000, Windows XP et Windows
Server 2003. Ils sont toutefois compatibles avec UTF-8. C'est pourquoi l'utilisation
d'un format de stockage UTF-8 dans la base de données nécessite de nombreuses
conversions supplémentaires. De façon générale, les ressources supplémentaires
nécessaires pour la conversion n'affectent pas le moteur de base de données
SQL Server, mais elles peuvent potentiellement affecter de nombreuses opérations
côté client.
UTF-8 peut être plus lent pour un grand nombre d'opérations de chaîne. Le tri, la
comparaison et presque n'importe quelle opération de chaîne peuvent être ralentis car
les caractères n'ont pas de largeur fixe.
UTF-8 a souvent besoin de plus de 2 octets et l'augmentation de la taille peut produire
un plus grand encombrement sur le disque et dans la mémoire.
Malgré ces inconvénients, étant donné que XML est devenu une norme importante pour la
communication sur Internet, vous souhaiterez peut-être envisager d'utiliser UTF-8 par défaut.
Remarque : Les anciennes versions d'Oracle et Java utilisent également UCS-2 et ne
peuvent pas reconnaître les paires de substitution. Oracle Corporation a commencé à prendre
en charge Unicode comme jeu de caractères de base de données dans Oracle 7. Oracle prend
actuellement en charge deux méthodes de stockage des données Unicode : (1) UTF-8 comme
schéma de codage des types de données de caractères CHAR et VARCHAR2, et pour tous les
noms et littéraux de SQL ; (2) UTF-16 pour le stockage des types de données Unicode
NCHAR, NVARCHAR et NCLOB. Oracle vous permet d'utiliser les deux méthodes en même
temps.
UTF-16
UTF-16 est le schéma de codage utilisé chez Microsoft et dans le système d'exploitation
Windows. UTF-16 est une extension destinée à gérer 1 048 576 caractères supplémentaires.
La nécessité d'une plage de substitution a été reconnue avant même l'apparition d'Unicode 2.0,
car il était devenu évident que l'objectif d'Unicode d'utiliser un seul point de code pour chaque
caractère de chaque langue ne pourrait pas être atteint en utilisant seulement
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
1
/
82
100%