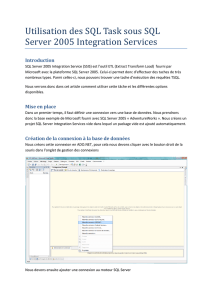
Modèle de données - Microsoft Center

Choisir une expérience de modélisation
tabulaire ou multidimensionnelle dans
SQL Server 2012 Analysis Services
Article technique Microsoft Business Intelligence
Auteurs
Conseil Hitachi :
Liz Vitt - Auteur
Scott Cameron - Auteur
Hilary Feier - Relecteur
Microsoft :
T.K. Anand - Relecteur
Ashvini Sharma - Relecteur
Date de publication : mai 2012
S'applique à : SQL Server 2012 Analysis Services
Résumé : ce livre blanc fournit une aide pratique aux professionnels et aux décideurs
BI afin qu'ils puissent déterminer si la modélisation tabulaire ou multidimensionnelle
SQL Server Analysis Services 2012 est le meilleur choix pour leur prochaine solution BI.

2
Choisir un paradigme de modélisation des données dans SQL Server 2012 Analysis Services
Copyright
Ce document est fourni « en l'état ». Les informations et les opinions exprimées dans
ce document, y compris les adresses URL et les autres références à des sites Internet,
peuvent faire l'objet de modifications sans préavis. Vous assumez tous les risques liés
à son utilisation.
Ce document ne vous concède aucun droit de propriété intellectuelle portant sur les
produits Microsoft. Vous pouvez copier et utiliser ce document à titre de référence
pour un usage interne.
© 2012 Microsoft Corporation. Tous droits réservés.

3
Choisir un paradigme de modélisation des données dans SQL Server 2012 Analysis Services
Sommaire
Introduction ................................................................................................................................................... 5
Informations de base sur la modélisation BISM ............................................................................... 5
Modélisation multidimensionnelle ................................................................................................... 5
Modélisation tabulaire .......................................................................................................................... 6
Outils d'analyse clients BISM ................................................................................................................... 7
Modèle de données .................................................................................................................................... 7
Relations de données ............................................................................................................................ 7
Relations un-à-plusieurs .................................................................................................................. 7
Relations plusieurs-à-plusieurs ...................................................................................................... 8
Relations de référence ...................................................................................................................... 8
Hiérarchies ................................................................................................................................................. 9
Hiérarchies standard .......................................................................................................................... 9
Hiérarchies déséquilibrées .............................................................................................................. 9
Hiérarchies parent-enfant ................................................................................................................ 9
Fonctionnalités de modélisation supplémentaires ................................................................... 10
Logique métier ........................................................................................................................................... 12
Transformations au niveau des lignes ........................................................................................... 12
Valeurs agrégées ................................................................................................................................... 13
Calculs ....................................................................................................................................................... 13
Scénarios de logique métier ............................................................................................................. 15
Logique de hiérarchie ..................................................................................................................... 15
Cumuls personnalisés ..................................................................................................................... 15
Mesures semi-additives .................................................................................................................. 16
Time Intelligence ............................................................................................................................... 17
Indicateurs de performance clés ................................................................................................. 17
Conversion monétaire ..................................................................................................................... 17
Jeux nommés ..................................................................................................................................... 17
Accès aux données et stockage............................................................................................................ 19
Performances et extensibilité ............................................................................................................ 19
Modèles multidimensionnels ....................................................................................................... 19
Modèles tabulaires ........................................................................................................................... 20
Programmabilité .................................................................................................................................... 22
Sécurité .......................................................................................................................................................... 22
Sécurité au niveau de la ligne/de l'attribut .................................................................................. 23

4
Choisir un paradigme de modélisation des données dans SQL Server 2012 Analysis Services
Sécurité dynamique .............................................................................................................................. 23
Sécurité au niveau de la cellule et sécurité avancée ................................................................ 23
Résumé .......................................................................................................................................................... 24
Pour plus d'informations ......................................................................................................................... 29

5
Choisir un paradigme de modélisation des données dans SQL Server 2012 Analysis Services
Introduction
La modélisation des données est une discipline pratiquée depuis de nombreuses
années par les professionnels BI, avec un objectif commun : organiser des données
disparates dans un modèle analytique qui prend en charge de manière efficace et
efficiente les besoins de reporting et d'analyse de l'entreprise. La modélisation des
données a évolué au fil des années grâce à de nouvelles technologies et à de nouveaux
outils. Or, les organisations doivent aujourd'hui relever un nouveau défi, à savoir,
fusionner leurs paradigmes de modélisation de façon transparente et cohérente pour
satisfaire les divers besoins d'analyse, mais aussi pour en rendre l'expérience homogène
au sein de l'entreprise.
Avec SQL Server 2012, Microsoft peut les aider à atteindre cet objectif grâce
à l'introduction du modèle sémantique BI (BISM), un modèle unique qui prend
en charge une vaste gamme de rapports et d'analyses tout en fusionnant deux
expériences de modélisation Analysis Services en arrière-plan :
La modélisation multidimensionnelle, introduite par les services OLAP SQL
Server 7.0 et reprise dans SQL Server 2012 Analysis Services, permet aux
professionnels BI de créer des cubes multidimensionnels complexes utilisant
le traitement analytique en ligne traditionnel (OLAP).
La modélisation tubulaire, introduite par PowerPivot pour Microsoft Excel 2010,
fournit des fonctionnalités de modélisation des données libre-service aux
analystes d'entreprise et de données. L'expérience de modélisation tabulaire est
davantage accessible aux utilisateurs qui ont passé des années à exploiter des
données à l'aide d'outils bureautiques tels qu'Excel et Microsoft Access. Dans
SQL Server 2012, la modélisation tabulaire a été étendue pour permettre aux
professionnels BI de créer des modèles tabulaires dans Analysis Services, ou
d'importer un modèle tabulaire PowerPivot dans Analysis Services. Notez que le
modèle PowerPivot ne peut pas être importé dans un modèle multidimensionnel
Analysis Services.
L'objectif de ce livre blanc est de vous aider à déterminer quelle expérience de
modélisation SQL Server 2012 Analysis Services (tabulaire ou multidimensionnelle)
convient le mieux à votre prochaine solution BI. Les descriptions et les recommandations
de produits de ce document se réfèrent à SQL Server 2012 Analysis Services, disponible
depuis mars 2012. Les caractéristiques du produit et les recommandations sont
susceptibles de changer au fil de l'évolution de la modélisation multidimensionnelle
ou tabulaire d'Analysis Services, dans les versions ultérieures de SQL Server.
Informations de base sur la modélisation BISM
Avant d'aborder de façon approfondie les différences entre la modélisation
multidimensionnelle et la modélisation tabulaire, commençons par une brève
présentation des expériences de modélisation BISM fournies par SQL Server 2012
Analysis Services.
Modélisation multidimensionnelle
Globalement, la modélisation multidimensionnelle crée des cubes composés de mesures
et de dimensions basées sur les données contenues dans une base de données
relationnelle. Pour utiliser ce paradigme, le serveur Analysis Services doit être configuré
pour s'exécuter en mode multidimensionnel, sa valeur par défaut. Dans ce mode,
le moteur OLAP utilise le modèle multidimensionnel pour préagréger d'importants
volumes de données et garantir un temps de réponse à la requête rapide. Le moteur OLAP
peut stocker ces agrégations sur un disque avec stockage OLAP multidimensionnel
(MOLAP) ou dans la base de données relationnelle avec stockage OLAP relationnel
(ROLAP).
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
1
/
29
100%