1 - Introduction : Différents types de bases de données

Page 1 sur 16
Bases de données relationnelles
Cours
Les bases de données rélationnelles sont un type particulier de bases de données, dans lequel les données
sont présentées et maniuplées à travers des tables.
Après avoir replacé dans sont contexte ce type de bases de données dans l’ensemble des types de bases de
données qui sont définis et utilisés actuellement, nous présenterons les bases de données relationnelles et
en particulier le vocabulaire spécifique qui est utilisé dans ce domaine pour décrire les tables et autres
éléments.
Nous présenterons la méthode utilisée pour définir une base de données qui répond aux besoins et
exigences d’un projet, et le passage à l’implémentation, c’est-à-dire le processus de conception du modèle
conceptuel de données et sa transformation en le modèle logique correspondant.
1 - Introduction : Différents types de bases de données
Il existe actuellement cinq grands types de bases de données :
Les bases hiérarchiques
Ce sont les premiers SGBD apparus. Elles font partie des bases navigationnelles constituées d’une gestion
de pointeurs entre les enregistrements. Le schéma de la base doit être arborescent.
Les bases réseaux.
Sans doute les bases les plus rapides, elles ont très vite supplanté les bases hiérarchiques dans les années
soixante-dix. Ce sont aussi des bases navigationnelles qui gèrent des pointeurs entre les enregistrements.
Cette fois-ci, le schéma de base est beaucoup plus ouvert.
Les bases relationnelles.
À l’heure actuelle, ce sont les plus utilisées. Les données y sont représentées en tables. Elles sont basées
sur l’algèbre relationnelle et un langage déclaratif (généralement SQL).
Les bases déductives.
Les données y sont représentées en tables (prédicats), le langage d’interrogation se base sur le calcul des
prédicats et la logique du premier ordre.
Les bases objets.
Les données y sont représentées en tant qu’instance de classes hiérarchisées. Chaque champ est un objet.
De ce fait, chaque donnée est active et possède ses propres méthodes d’interrogation et d’affectation.
L’héritage est utilisé comme mécanisme de factorisation de la connaissance.
La répartition du parc des SGBD n’est pas équitable entre ces 5 types de base : 75% sont relationnels,
20% réseaux, les 5% restants étant partagés entre bases déductives et objets. Ces chiffress risquent
néanmoins d’évoluer d’ici quelques années, et la frontière entre bases relationnelles et objets pourrait être
éliminée par l’introduction d’une couche objets sur les bases relationnelles.
Quelques systèmes reconnus :
Oracle
http://www.oracle.com
base relationnelle
DB2
http://www.software.ibm.com
base relationnelle
Sybase
http://www.sybase.com
base relationnelle
SQL Server
http://www.microsoft.com
base relationnelle
Ingres
ftp://s2k-ftp.CS.Berkeley.EDU/pub/ingres
base relationnelle
Informix
http://www.informix.com
base relationnelle
O2
http://www.o2tech.fr ou
http://www.ardentsoftware.com
base objet
Gemstone
http://www.gemstone.com
base objet
ObjectStore
http://www.objectdesign.com ou
http://www.odi.com
base objet
Jasmine
http://cai.com/jasmine
base objet
et des bases relationnelles sur micro :

Page 2 sur 16
Access 2000
http://www.microsoft.com
base relationnelle
Paradox 8.0
http://www.corel.com
"
Visual DBase
http://www.borland.com
"
FoxPro
http://www.microsoft.com
"
FileMaker
http://www.claris.fr
"
4D 6.5
http://www.aci.fr
"
Windev
http://www.pcsoft.fr
"
Il existe aussi quelques freewares et sharewares que l’on peut trouver sur Internet pour s’initier aux bases
de données relationnelles comme :
MySQL
http://www.mysql.net ou
http://www.mysql.com
MSQL
http://Hughes.com.au
Postgres
http://www.postgresql.org
InstantDB
http://www.microsoft.com
Entièrement écrit en Java
2 - Les modèles de données
a) Les niveaux ANSI/SPARC
Pour assurer les objectifs précédemment décrits, les trois niveaux suivants de description (voir la figure
suivante) ont été distingués par le groupe ANSI/X3/SPARC en 1975 :
Le niveau conceptuel
Il correspond à ce que l’on retrouve dans la méthode Merise avec les modèles de données MCD
(modèle conceptuel de données) et MLD (modèle logique de données).
Le niveau interne
Il correspond à la structure de stockage des données : types de fichiers utilisés, caractéristiques des
enregistrements (longueur, composants), chemin d’accès aux données (type d’index, chaînages,
etc.).
Le niveau externe
Il est caractérisé par l’ensemble des vues externes qu’ont les groupes d’utilisateurs.
modèles externes
modèle externe modèle externe modèle externe
schéma conceptuel
schéma interne
Figure 1 : Le modèle Ansi/Sparc
Ces trois niveaux correspondent à trois métiers bien précis de l’entreprise. Le concepteur de SGBD
s’occupe principalement du schéma interne. Il travaille sur les structures de données de base,
l’optimisation des techniques d’accès aux données (qu’on appelle « techniques de hachage ») et les
dispositifs d’optimisation des requêtes (notamment en définissant des index). L’administrateur de bases

Page 3 sur 16
de données conçoit les bases, organise les tables, optimise les requêtes (notamment en définissant des
index) et gère les droits d’accès. Enfin les développeurs et utilisateurs écrivent les programmes applicatifs
et utilisent les outils de haut niveau du SGBD permettant une abstraction logique sur les données
(notamment les vues).
Pour s’attaquer à tout problème, il est toujours nécessaire de réfléchir profondément aux tenants et
aboutissants de ce que l’on veut réaliser. La phase de conception nécessite souvent de nombreux choix qui
auront parfois des répercussions importantes par la suite. La conception des bases de données ne fait pas
exception à la règle. Les théoriciens de l’information ont donc proposé des méthodes permettant de
structurer un projet et de présenter de manière abstraite le travail que l’on souhaite réaliser. Ces méthodes
ont donné naissance à une discipline, l’analyse, et à un métier, l’analyste.
L’analyse est la discipline qui étudie et présente abstraitement le travail à effectuer. La phase d’analyse est
très importante puisque c’est elle qui sera validée par les utilisateurs avant la mise en œuvre du système
concret. Il existe de nombreuses méthodes d’analyse (AXIAL, OMT, etc.), la plus utilisée en France étant
la méthode Merise. Merise sépare les données et les traitements à effectuer avec le système d’information
en différents modèles conceptuels et physiques. Le plus intéressant pour la conception d’une base de
données est le MCD.
Le MCD (modèle conceptuel de données) est un modèle abstrait de la méthode Merise permettant de
représenter l’information d’une manière compréhensible aux différents services de l’entreprise. Il permet
une description statique du système d’information à l’aide d’entités et d’associations.
Le travail de création d’une base de données par le concepteur commence juste après celui des analystes
qui ont établi le MCD.
b) Définitions
La propriété est une donnée élémentaire et indécomposable du système d’information, par exemple, une
date de début de projet, la couleur d’une voiture, une note d’étudiant.
L’entité est la représentation, dans le système d’information, d’un objet matériel ou immatériel ayant une
existence propre et conforme aux choix de gestion de l’entreprise. L’entité est composée de propriétés.
Par exemple, une personne, une voiture, un client, un projet sont en général des entités.
nom de l’ entité
.
.
.
li ste des propriétés
.
.
Figure 2 : Représentation graphique d'une entité
L’association traduit dans le système d’information le fait qu’il existe un lien entre différentes entités. Le
nombre d’intervenants dans cette association caractérise sa dimension :
réflexive sur une même entité ;
binaire entre deux entités ;
ternaire entre trois entités ;
n-aire entre n entités ;

Page 4 sur 16
Personne
nom
prénom
.
.
.
.
Service
type (admi n, scola...)
.
.
.
travaill e dans un
Figure 3 : Représentation graphique d’une association binaire
Matériel
numMat
.
.
.
.
est composé de
0,n
0,n
Figure 4 : Lien réflexif typique
Avion
numAvion
.
.
.
.
Pilote
numPilote
.
.
.
Lign e
numLigne
.
.
.
Vol
0,n 0,n
0,n
Figure 5 : Lien ternaire typique
Des propriétés peuvent être attachées aux associations. Par exemple, un employé peut passer 25% de son
temps dans un service et 75% de son temps dans un autre. L’association « travaille dans » qui relie une
personne à un service portera dans ce cas la propriété « volume de temps passé ».
Les cardinalités caractérisent le lien entre une entité et une association. La cardinalité d’une association
est constituée d’une borne minimale et d’une borne maximale :
minimale : nombre minimal de fois qu’une occurrence d’une entité participe aux occurrences de
l’association, généralement 0 ou 1 ;
maximale : nombre maximal de fois qu’une occurrence d’une entité participe aux occurrences de
l’association, généralement 1 ou n.
Les cardinalités maximales sont nécessaires pour la création de la base de données. Les cardinalités
minimales sont nécessaires pour exprimer les contraintes d’intégrité.

Page 5 sur 16
Personne
nom
prénom
.
.
.
.
Service
admi nistration
gestion
informatique.
.
.
.
travaille dans un
volume
1,n 1,n
Figure 6 : Représentation des cardinalités
De la Figure 6, on déduit qu’ « une personne peut travailler dans un ou plusieurs services ». On constate
de plus que « dans chaque service, il y a au moins une personne mais il peut y en avoir plusieurs ». Enfin,
une mesure du « volume de travail » est stockée pour chaque personne travaillant dans un service donné.
Remarque : Il existe une notation des cardinalités « à l’américaine » dans laquelle on ne note que les
cardinalités maximales. Il peut donc y avoir deux sortes de cardinalités « américaines » : (1 : n) et (n : m).
Dans la figure précédente, la notation américaine serait n : m, puisuq’une personne peut travailler dans
plusieurs services et que, dans un service, il peut y avoir plusieurs personnes.
Un lien hiérarchique est un lien 1 : n en notation américaine.
Un lien maillé est un lien n : m en notation américaine.
Seules les cardinalités maximales permettent de déterminer le nombre de tables. Les cardinalités
minimales servent à exprimer certaines contraintes d’intégrité mais ne modifient en aucun cas la structure
des tables de la base.
L’identifiant d’une entité est constitué d’une ou plusieurs propriétés de l’entité de sorte que, à chaque
valeur de l’identifiant corresponde une et une seule occurrence de l’entité. L’identifiant d’une association
est constitué de la réunion des identifiants des entités qui participent à l’association.
Dans la Figure 4, l’entité Matériel a pour identifiant, le numéro de matériel. Dans ce lien réflexif
d’une entité sur elle-même, un matériel peut être constitué d’un ou plusieurs autres matériels et vice-
versa.
La Figure 5, avec les entités Avion, Pilote et ligne, reliées par l’association ternaire définissant le
Vol. Un vol est ici caractérisé un numéro d’avion fixé, un numéro de pilote fixé et un numéro de ligne
fixé. Il en résulte qu’un pilote peut voler avec des avions différents sur une même ligne.
L’identifiant est représenté en souligné dans le MCD. Il constituera par la suite, la clé d’une table
relationnelle.
La conception d’un MCD avec de nombreuses entités est parfois une tâche ardue et nécessite un savoir-
faire que seuls les analystes professionnels peuvent acquérir par l’expérience. La gestion des dates, par
exemple, est souvent délicate. Dans le MCD de l’illustration suivante, la relation entre Salariés et Tâche
est constitué d’un lien maillé dont les dates sont de simples propriétés. Il en résulte qu’un salarié ne
pourra participer plusieurs fois à la même tâche ! En effet, la clé de la table correspondant à l’association
sera constituée du couple (numéro de salarié, numéro de tâche) qui devra donc être unique.
Dans de nombreux MCD, on est souvent obligé de créer une entité Date dès qu’une date doit faire partie
d’une clé, et bien que l’on ne traduise jamais cette entité par une table.
Précisons enfin qu’il est toujours difficile de dissocier les données des traitements qui seront effectués. Le
MCD est donc généralement associé à un MCT (modèle conceptuel de traitements). Souvent, on modifie
le MCD ou directement le MLD (modèle logique de données), pour améliorer les traitements. C’est
pourquoi, dans l’exemple précédent, on ne crée pas une table pour les dates. Pendant la conception, on ne
traite que les cas « normaux », puis on vérifie et on modifie, si besoin, les modèles en fonction des cas
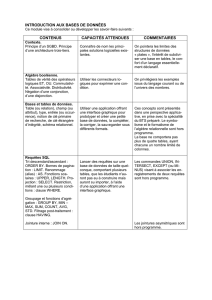
exceptionnels !Pourquoi une requête est-elle meilleure qu’une autre ?
 6
7
8
9
10
11
12
13
14
15
16
6
7
8
9
10
11
12
13
14
15
16
1
/
16
100%