ADN

Acide désoxyribonucléique et Acide
ribonucléique
Acide désoxyribonucléique : ADN
L'ADN, sigle de acide désoxyribonucléique, est une longue molécule que l'on retrouve dans
tous les organismes. L'ADN est présent dans le noyau des cellules eucaryotes, les cellules
procaryotes, dans les mitochondries ainsi que dans les chloroplastes. Les organismes vivants
les plus simples, les virus, sont constitués essentiellement d'une enveloppe (elle-même
constituée de protéines) et d'un brin d'ADN (ou d'ARN). On dit que l'ADN est le support de
l'hérédité car cette molécule a la faculté de se reproduire et d'être transmise aux descendants
lors des processus de reproduction des organismes vivants. Il est à la base de processus
biologiques importants aboutissant à la production des protéines. D'un point de vue chimique,
l'ADN est un acide faible.
Un peu d’histoire
Découverts en 1868 par le biologiste suisse Friedrich Mischer dans les noyaux cellulaires,
d’où leur nom, sont également présents dans le cytoplasme, les acides nucléiques sont des
molécules d’origine naturelle qui jouent un rôle fondamental dans la vie et la reproduction des
cellules animales, végétales et microbiennes.
Tels qu’on peut les isoler des tissus animaux ou végétaux, ces acides se présentent sous
forme de molécules géantes ou de macromolécules, dont la masse moléculaire est comprise
entre 25 000 et plusieurs centaines de millions. Les acides nucléiques sont constitués par
l’enchaînement de nombreux motifs relativement simples, dissociables par hydrolyse; chacun
d’eux comporte une base azotée (purique ou pyrimidique), un sucre à cinq atomes de carbone
ou pentose (ribose ou désoxyribose) et un acide phosphorique: ce sont donc des esters
phosphoriques complexes que l’on nomme nucléotides. La structure du pentose est à
l’origine de la classification des acides nucléiques naturels en deux catégories fondamentales:
d’une part, les acides ribonucléiques (ARN) contenant comme pentose le ribose ; d’autre part,
les acides désoxyribonucléiques (ADN) contenant comme pentose le désoxyribose .
Au début des années 50 et on ne sait presque rien sur l'ADN. Comment cette molécule peut-
elle se reproduire? Comment peut-elle dicter à la cellule comment synthétiser des protéines?
On n'en sait rien, mais on se doute que si on découvre comment est faite la molécule, quelle
est sa structure exacte, on pourra alors répondre à ces questions. Une course s'engage alors
entre différentes équipes à travers le monde. La première équipe qui parviendra à mettre en
évidence la structure de l'ADN est assurée d'un prix Nobel. C'est l'Anglais Francis Crick et
l'Américain James Watson qui remporteront cette course au Nobel en publiant, en 1953, dans
la revue Nature, un court article qui révolutionnera la biologie à partir de travaux effectués au

laboratoire Cavendish de Cambridge, le 25 avril 1953, que James Watson, alors âgé de 25 ans,
Francis Crick, physicien de formation. Il faut ajouter à ces noms celui de Rosalind Franklin,
qui n'obtint pas le prix Nobel pour diverses raisons. Ces travaux, ont établi par rayons X la
structure en double hélice de l'ADN.
Image d’un cliché de diffraction de rayons X par l’ADN : une structure en hélice s’en
déduit.
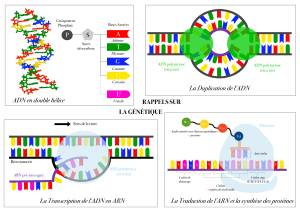
La double hélice : complémentarité des brins d'ADN
L'ADN (acide désoxyribonucléique) est une macromolécule biologique formée par deux
chaînes complémentaires qui s'emboîtent tout en s'enroulant l'une autour de l'autre pour
former une double hélice droite . Chaque chaîne est constituée d'un squelette formé de
phosphodiesters et de sucres (le ribose pour l’ARN, désoxyribose pour l’ADN ) en alternance.
Chaque sucre porte en plus une "lettre" (un groupe chimique appelé "base azotée") du livre
génétique; ces lettres sont A (pour adenine), T (thymine), G (guanine) et C (cytosine). C'est le
fait que les lettres A et T, ainsi que G et C, peuvent s'appareiller entre elles qui permet la

complémentarité des deux chaînes formant la double hélice. La complémentarité A-T et G-C
fait que l'on parle alors de "paires de bases".
La double hélice, avec les molécules d’eau qui lui sont associées a un diamètre de 20 à 25A°.
Sa longueur de persistance (longueur sur laquelle un polymère est à peu près rectiligne) est
de 500 A°. Avec le caractère acide de l’ADN la molécule dans l’eau est un ion négatif : il y a
une charge moins par paire de bases.

Nucléotides et leurs polymérisation : la chaîne formée est orientée de 3 vers 5 (on dit chaîne
3’-5’) en numérotant les atomes de carbones du cycle central (C1 à C5)

Les quatre bases : deux purines et deux pyrimidine
Appariement des bases par paires complémentaires à l’aide de liaisons hydrogènes. Les deux
brins antiparallèles d'ADN sont toujours étroitement reliés entre eux par des liaisons
hydrogène formées entre les bases complémentaires A-T et G-C. Ces deux brins d'ADN sont
dit complémentaires car les purines (Adénine et Guanine) d'un brin font toujours face à des
pyrimidines de l'autre brin (Thymine et Cytosine). Les nucléotides sont complémentaires entre
eux. Ainsi, l'adénine est complémentaire à la thymine et la guanine est complémentaires à la
cytosine. Deux liaisons hydrogène retiennent ensemble la paire A-T et trois retiennent la
paire G-C.
Les deux brins antiparallèles d'ADN sont toujours étroitement reliés entre eux par des liaisons
hydrogène formées entre les bases complémentaires A-T et G-C. Ces deux brins d'ADN sont
dit complémentaires car les purines (Adénine et Guanine) d'un brin font toujours face à des
pyrimidines de l'autre brin (Thymine et Cytosine). Les nucléotides sont complémentaires
 6
7
8
9
10
11
12
13
6
7
8
9
10
11
12
13
1
/
13
100%






![86 [Quels sont les constituants de l`ADN et de l`ARN? ] ADN](http://s1.studylibfr.com/store/data/007383263_1-9a41736365764fe43d1f9e7462bcdc21-300x300.png)


