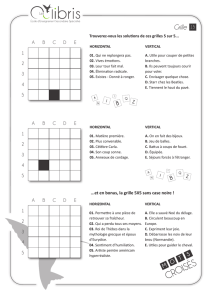
TRAITEMENTS DES DONNÉES

1
TRAITEMENT DES DONNÉES
Nous aurons l'occasion d'accumuler rapidement un grand nombre de résultats qu'il peut
être utile de résumer, au moins sommairement.
Il faut savoir que ce qui constitue une bonne méthode de résumer l'information est
déterminée par l'utilisation qu'on en fera.
Nous présentons ici quelques procédures standard de traitement des données pour
donner un support à ce que nous ferons à l'aide d'Excel.
Représentation des données
Un contractant s'intéresse au temps mis par une équipe pour préparer 1 km à recevoir
de l'asphalte. À partir de ses dossiers historiques, il obtient l'information suivante (en
heures)
6.2 8.5 7.2
5.4 7.4 6.4
7.3 6.8 7.6
8.8 5.6 7.2
9.2 7.6 8.6
7.5 8.3 6.6
6.7 9.1 8.3
12.1 8.7 7.2
10.2 9.2 8.8
8.3 5.6 7.1
Ce groupe de 30 données brutes contient toute l'information disponible au contractant
mais ne présente sous cette forme qu'un tableau de chiffres sans grande signification.

2
Une façon pratique d'organiser les données est de les regrouper par intervalle de
données. Chaque intervalle sera nommé une classe, de façon générale, on parlera
alors de données regroupées en classes. La largueur de l'intervalle se nomme
l'amplitude de la classe.
Il n'y a pas de règle formelle quant au nombre de classes à constituer. En général, on
utilise entre 5 et 10 classes selon le niveau de détail désiré.
On remarquera que la plus petite valeur observée est 5.4 et que la plus grande des
valeurs est 12.1. Les observations ont alors une "étendue" (range) de
12.1 - 5.4 = 6.7 ( Max ( ) - Min ( ) )
Si on choisit de faire 8 classes (12.5 - 4.5 = 8), les "centres de classes" seront
entiers. Ce critère détermine le nombre de classes de façon à ce que les centres de
classes soient des nombres faciles à utiliser est un des plus utilisé.
Nous constituons la liste des intervalles en indiquant leurs bornes et les centres de
classes, puis nous parcourons les données et affectons chaque donnée à la classe à
laquelle elle appartient.
Classe
Centre
Affectation
Nombre
d’observations
fréquence
absolue effectif
Proportion des
observations dans
classe fréquence
relative
5.55.4
5
1
1
1/30
5.65.5
6
1111
4
4/30
5.75.6
7
11111 1111
9
9/30
5.85.7
8
11111 1
6
6/30
5.95.8
9
11111 111
8
8/30
5.105.9
10
1
1
1/30
5.115.10
11
-
0
0
5.125.11
12
1
1
1/30

3
Une parenthèse indique que la borne est exclue et un crochet indique que la borne est
incluse.
Représentation graphique
À partir des données recensées dans le tableau précédent nous pouvons obtenir une
représentation graphique simple qui rend un portrait efficace des données sans sacrifier
trop d’information. Ce graphique est l’histogramme.
Pour les données du contractant, l’histogramme est obtenu à partir du tableau des
données regroupées en classe sur l’axe horizontal nous inscrivons les intervalles et sur
l’axe vertical un rectangle dont la hauteur représente le nombre d’observations dans la
classe.
histogramme
0
2
4
6
8
10
5 6 7 8 9 10 11 12
heures
effectifs
Series1
Une autre représentation graphique utile est celle de la fréquence cumulée et du
polygone de fréquence cumulé. On commence par étendre le tableau en y insérant une
colonne de fréquence cumulée (effectif cumulé).

4
Un plan graphique est constitué de lignes horizontales et verticales. Une des lignes
horizontales est nommée l’axe horizontal et une des lignes verticales est appelée l’axe
vertical.
Le point où les deux lignes se croisent est appelé origine. Chaque point dans le plan
peut être représenté par une paire de nombres qui est nommée coordonnée. La
première coordonnée est aussi appelée abscisse et représente la distance horizontale
du point de l’axe vertical. La deuxième coordonnée est nommée l’ordonnée et
représente la distance verticale du point de l’axe horizontal.
Les points dessous l’axe horizontal auront une ordonnée négative et les points à
gauche de l’axe vertical, une abscisse négative.
Souvent l’axe horizontal sera nommé « axe des abscisses » et l’axe vertical « axe des
ordonnées ».
Graphique fréquence cumulée
Sur un graphique, on reporte les bornes des classes sur l’axe horizontal, la hauteur de
la classe représente les effectifs cumulés (ou la fréquence relative cumulée).
effectifs
frequence
no de la classe
borne inf
BorneSup
centre
effectifs
cumules
cumulee
1
4.5
5.5
5
1
0.033333
1
0.033333
2
5.5
6.5
6
4
0.133333
5
0.166667
3
6.5
7.5
7
9
0.3
14
0.466667
4
7.5
8.5
8
6
0.2
20
0.666667
5
8.5
9.5
9
8
0.266667
28
0.933333
6
9.5
10.5
10
1
0.033333
29
0.966667
7
10.5
11.5
11
0
0
29
0.966667
8
11.5
12.5
12
1
0.033333
30
1

5
Cf
Graphique polygone fréquence cumulée
Le polygone de fréquence cumulée est obtenu en traçant une droite entre les centres
de classes, une classe artificielle d’égale amplitude est introduit avant la première
classe.
 6
7
8
9
6
7
8
9
1
/
9
100%