Use of Machine Learning in Bioinformatics to Identify Prognostic and

Use of Machine Learning in
Bioinformatics to Identify Prognostic and
Predictive Molecular Signatures in
Human Breast Cancer
Benjamin Haibe-Kains
Universit ´
e Libre de Bruxelles Institut Jules Bordet

Table of Contents
Thesis and Contributions
Machine Learning in Bioinformatics
Breast Cancer
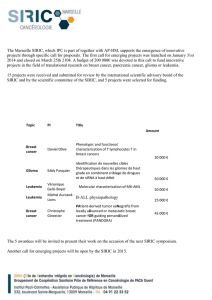
TAMOXIFEN c
°Resistance
Methods and Results
Methodology
Feature Selection
Cutoff Selection
Validation on Test Set
Gene Ontology
Conclusion
Future Works
Benjamin Haibe-Kains Thesis Presentation – p.1/33

Thesis and Contributions
Benjamin Haibe-Kains Thesis Presentation – p.2/33

Thesis and Contributions
Thesis concerns cancer classification using machine
learning methods and survival analysis based on
gene expression data.
My contributions :
Methodology (Chapter 4)
Preprocessing methods (Sections 4.2.2 and 4.2.3)
Feature selection (Section 4.3)
Classifier validation on different microarray
platforms (Section 4.3.2.1)
Time-dependent ROC curve (Section 4.5.4)
Cutoff selection (Section 4.4.2)
Benjamin Haibe-Kains Thesis Presentation – p.3/33

Machine Learning in
Bioinformatics
Benjamin Haibe-Kains Thesis Presentation – p.4/33
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
1
/
66
100%