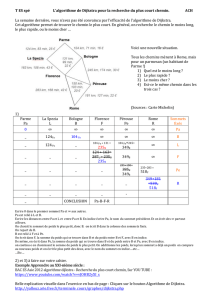
6.2 Les problèmes de chemins optimaux

2e édition 2003
© Groupe Eyrolles, 1994, 2003,
ISBN : 2-212-11385-4

CHAPITRE 6
Problèmes de chemins
optimaux
6.1 Introduction
Nous commençons, avec ce chapitre consacré aux problèmes de chemins, l’étude des
principaux problèmes d’optimisation dans les graphes. Les problèmes de chemins optimaux
sont très fréquents dans les applications pratiques. On les rencontre dès qu’il s’agit
d’acheminer un objet entre deux points d’un réseau, de façon à minimiser un coût, une
durée, etc. Ils apparaissent aussi en sous-problèmes de nombreux problèmes combinatoires,
notamment les flots dans les graphes et les ordonnancements. Tout ceci a motivé très tôt la
recherche d’algorithmes efficaces. Les méthodes qui font l’objet de ce chapitre sont celles
présentées sur la figure 6–1.
T_GRAPHE_LISTE
- HEAD: THEAD;
- SUCC: TSUCC;
- W: PTArcCost;
- M: ARCNUM;
+ Bellman (var W:TArcCost; s:Node; var V:TNodeCost; var P:TNodeInfo; var NegCirc:Boolean);
+ Dijkstra (var W:TArcCost; s,t:Node; var V:TNodeCost; var P:TNodeInfo);
+ Floyd (var W:TArcCost; var V:CostMatrix; var P:NodeMatrix; var NegCirc:Boolean);
+ Schedule (var W:TArcCost; Alpha,Omega:Node;var V:TNodeCost; var P:TNodeInfo);
+ DijHeap (var W:TArcCost; s,t:Node; var V:TNodeCost; var P:TNodeInfo);
+ Bucket (var W:TArcCost; s,t:Node; var V:TNodeCost; var P:TNodeInfo);
+ ESOPO (var W:TArcCost; s:Node; var V:TNodeCost; var P:TNodeInfo);
+ FIFO (var W:TArcCost; s:Node; var V:TNodeCost; var P:TNodeInfo);
Figure 6–1. Les méthodes de cheminement optimal de la classe T_GRAPHE_LISTE

176 ______________________________________________________ Algorithmes de graphes
Dans une première partie, nous définissons les principaux problèmes de chemins optimaux,
nous précisons la distinction entre algorithmes à fixation et à correction d’étiquettes, puis
nous donnons la liste des principaux algorithmes. Nous terminons cette partie par quelques
exemples d’utilisation. La seconde partie présente un ensemble choisi d’algorithmes. Elle
est consacrée aux problèmes de loin les plus fréquents, où le coût d’un chemin, à optimiser,
est la somme des coûts de ses arcs. Pour ce groupe de problèmes, nous présentons :
des algorithmes à fixation d’étiquettes ;
des algorithmes à correction d’étiquettes.
Le chapitre se conclut par deux applications. La première concerne les problèmes
d’ordonnancement à contraintes de précédence, popularisés par la gestion de projets. La
seconde est une évaluation comparative des algorithmes du chapitre sur des graphes de
tailles et densités variables.
6.2 Les problèmes de chemins optimaux
6.2.1 Les grands types de problèmes
Considérons un graphe orienté valué G = (X,A,W). X désigne un ensemble de N sommets
(ou nœuds) et A un ensemble de M arcs. W(i,j), aussi noté Wij, est la valuation (aussi
appelée poids ou coût) de l’arc (i,j), par exemple une distance, un coût de transport, ou un
temps de parcours.
Pour la fonction économique la plus répandue, le coût d’un chemin entre deux sommets est
la somme des coûts de ses arcs. Les problèmes associés consistent à calculer des chemins
de coût minimal (en abrégé chemin minimaux, ou plus courts chemins). Ils ont un sens si G
n’a pas de circuit de coût négatif, sinon on pourrait diminuer infiniment le coût d’un
chemin en tournant dans un tel circuit, appelé pour cette raison circuit absorbant. Bien
entendu, on peut aussi chercher des chemins de valeur maximale, problème n’ayant de sens
qu’en l’absence de circuits positifs.
En l’absence de circuit absorbant, on peut restreindre la recherche des plus courts chemins
aux seuls chemins élémentaires, c’est-à-dire ne passant pas deux fois par un même sommet.
En effet, si un chemin emprunte un circuit, on peut enlever la portion passant par le circuit
sans augmenter le coût. Le problème de recherche d’un chemin optimal en présence de
circuits absorbants existe, mais il est NP-difficile [Gare79].
Il existe d’autres fonctions économiques que la somme des coûts des arcs, mais elles sont
moins répandues dans les applications. Ainsi, si on interprète les valuations comme des
capacités, on peut définir la capacité d’un chemin comme le minimum des valeurs de ses
arcs et chercher des chemins de capacité maximale [Gon95]. On peut aussi s’intéresser à la
valeur moyenne d’un chemin, somme des coûts de ses arcs divisée par le nombre d’arcs, et
calculer un chemin de valeur moyenne minimale [Gon95,Ahu93].
Nous étudions dans ce chapitre uniquement les problèmes où le coût d’un chemin est la
somme des coûts de ses arcs. La littérature distingue trois types de problèmes, que nous
notons A, B et C :

Chapitre 6 – Problèmes de chemins optimaux _________________________________ 177
Problème A : Etant donné deux sommets s et t, trouver un plus court chemin de s à t.
Problème B : Etant donné un sommet de départ s, trouver un plus court chemin de s
vers tout autre sommet.
Problème C : Trouver un plus court chemin entre tout couple de sommets, c’est-à-dire
calculer une matrice N × N appelée distancier.
Ces problèmes sont liés. Un algorithme pour A peut bien sûr être appliqué plusieurs fois
pour résoudre B ou C. Un algorithme pour B peut construire un distancier si on l’applique à
chaque sommet de départ possible s : une exécution calculera en fait la ligne n°s du
distancier. Certains algorithmes pour B ont la propriété de traiter définitivement un sommet
de destination à chaque itération. Ils peuvent donc résoudre A en étant stoppés dès que
x = t. Bien entendu, on ne gagne rien si t est traité en dernier !
A part certains algorithmes conçus spécifiquement pour calculer les k meilleurs chemins
entre deux sommets, les algorithmes pour les problèmes A, B et C ne construisent qu’un
des chemins possibles parmi ceux de coût minimal joignant deux sommets. La raison est
qu’il existe dans le pire des cas un nombre énorme de chemins de même coût : il serait
impossible de les donner tous.
Par conséquent, pour le problème A, le seul chemin élémentaire optimal conservé peut être
stocké dans une liste d’au plus N sommets. En fait, comme pour l’exploration de graphe
vue dans le chapitre 2, un seul tableau de N sommets suffit pour stocker N-1 chemins
élémentaires optimaux de s vers tout autre sommet (problème B).
Il suffit de stocker pour tout sommet x son prédécesseur unique P[x] (appelé aussi père
de x), le long du chemin optimal de s à x. P code, en fait, “à l’envers” l’arborescence des
plus courts chemins développée par l’algorithme (anti-arborescence). Cette technique peut
être appliquée à un distancier (problème C). Pour chaque ligne s du distancier, un tableau
de N éléments stocke les chemins optimaux de s vers tout autre sommet. On peut donc
stocker un chemin optimal entre tout couple de sommets avec une matrice N × N de même
taille que le distancier.
6.2.2 Les deux familles d'algorithmes
Sauf deux exceptions (l’algorithme de Sedgewick-Vitter pour le problème A et celui de
Floyd-Warshall pour le problème C), les algorithmes de ce chapitre concernent le problème
B. Tous calculent pour chaque sommet x une étiquette (label) V[x], valeur des plus courts
chemins du sommet de départ au sommet x. Cette valeur représente au début une estimation
par excès (majorant) de la valeur des plus courts chemins.
Comme indiqué en 6.2.1, certains algorithmes traitent définitivement un sommet à chaque
itération : ils sélectionnent un sommet x et calculent la valeur définitive de V[x]. Ces
algorithmes sont dits à fixation d’étiquettes (label setting algorithms) et sont représentés
par l’algorithme de Dijkstra et ses dérivés. Ils sont étudiés en 6.3. D’autres algorithmes
peuvent affiner jusqu’à la dernière itération l’étiquette de chaque sommet. On les appelle
algorithmes à correction d’étiquettes (label correcting algorithms).
Voici la structure générale d’un algorithme à correction d’étiquettes. Le sommet de départ
est noté s. Le tableau V des étiquettes donne à la fin le coût du plus court chemin trouvé de

178 ______________________________________________________ Algorithmes de graphes
s vers tout autre sommet. P[x] stocke le père de x le long de ce chemin. Par convention,
P[x] = 0 signifie que x n’a pas été atteint par un chemin d’origine s. L’ensemble E désigne
les sommets dits ouverts, dont l’étiquette vient d’être améliorée. Ces sommets sont en
attente de balayage de leurs successeurs, pour essayer de propager l’amélioration de V[x].
{Initialisation}
Initialiser le tableau V à +∞
Initialiser le tableau P à 0
V[s] := 0
P[s] := s
E := {s}
{Boucle principale}
Tant que E ≠ ∅
Enlever un sommet quelconque i de E
Pour tout successeur j de i tel que V[i] + W(i,j) < V[j]
V[j] := V[i] + W(i,j)
P[j] := i
Ajouter j à E (s'il n'y est pas déjà)
FP
FP.
6.2.3 Liste des principaux algorithmes
Problème A
Le problème A est en général résolu par un algorithme à fixation d’étiquettes pour le
problème B, qu’on stoppe dès que le sommet de destination choisi est traité définitivement.
Il existe cependant un algorithme conçu spécifiquement pour le problème A, celui de
Sedgewick et Vitter [Mch90,Sed86]. Cet algorithme en O(M.log N) est valable pour les
graphes dits euclidiens, où les sommets sont des points de l’espace euclidien et où le coût
d’un arc est la distance euclidienne entre ses extrémités.
Problème B
Cas W = constante. Le problème revient à trouver des plus courts chemins en nombre
d’arcs. Il peut se résoudre par une exploration de graphe en largeur, implémentable en
O(M). Ce problème a déjà été vu au chapitre 2.
Cas W ≥
≥≥
≥ 0. On peut le résoudre en O(N2) par un algorithme à fixation d'étiquettes dû à
Dijkstra [Gon95]. Avec une structure de tas, on obtient une variante en O(M.log N),
intéressante si G est peu dense [Cor01,Mch90,Gon95]. Si les coûts sont entiers et si leur
valeur maximale U n'est pas trop grande, une structure de données appelée bucket
permet un comportement moyen en O(M + U), la complexité au pire étant O(N2 + U)
[Div90,Hun88,Den79,Dia79]. Il existe enfin une structure hybride entre tas et buckets,
le tas redistributif, donnant un algorithme en O(M + N.log U) [Ahu90].
W quelconque. L’algorithme à correction d'étiquettes de Bellman [Gon95] est une
méthode très connue, de type programmation dynamique, résolvant ce cas général en
O(N.M). Il peut aussi servir à détecter la présence d'un circuit de coût négatif. Il existe
une implémentation connue sous le nom de FIFO et basée sur une file de sommets.
D'Esopo et Pape ont proposé une version ayant un très bon comportement moyen sur les
graphes peu denses [Pap80].
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
1
/
41
100%