LES BASES DE DONNEES RELATIONNELLES

LES BASES DE DONNEES RELATIONNELLES
1 GENERALITES
1.1 Introduction
Dans beaucoup de domaines, on manipule des données ayant la même structure.
Toutes ces données ayant la même structure constituent une base de données. On utilise aussi
le terme BDD ou le terme anglais Data Base.
Une base de données est un ensemble structuré de données gérées à l’aide d’un ordinateur.
Dans une entreprise, une base de donnée concerne
•Les fournisseurs
•Les clients
•Les commandes
•Les factures…
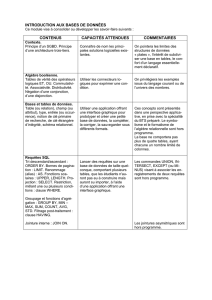
1.2 Le stockage des données (les tables)
Des données ayant la même structure sont rangées dans un même tableau appelé table.
Toutes les données d’une même colonne sont du même type. Elles sont nommées champs.
Chaque ligne est appelée enregistrement ou entrée.
Exemple :
La table ci-dessus contient :
3 entrées (3 lignes de données).
7 champs (id, Nom, Prénom, Sexe, Adresse, Ville, Code postal).
1.3 Les principaux types de données de MySQL
Pour plus d’informations: http://dev.mysql.com/doc/refman/5.0/fr/
1.3.1 Les types numériques
•TINYINT, BIT, BOOL, BOOLEAN : 1octet
•SMALLINT : 2 octets
•MEDIUMIN : 3 octets
•INT, INTEGER : 4 octets
•BIGINT : 64 octets
•FLOAT : Un petit nombre à virgule flottante, en précision simple.
•DOUBLE : Un nombre à virgule flottante, en précision double.

•DECIMAL : Un nombre à virgule flottante littéral. Il se comporte comme une colonne de
type CHAR. Cela signifie que le nombre est stocké sous forme de chaîne : chaque
caractère représente un chiffre.
1.3.2 Les types de données temporels : dates et heures
•DATE : MySQL affiche les valeurs de type DATE au format 'YYYY-MM-DD', mais
vous permet d'assigner des valeurs DATE en utilisant plusieurs formats de chaînes et
nombres.
•DATETIME : Une combinaison de date et heure. MySQL affiche les valeurs de type
DATE au format 'YYYY-MM-DD HH:MM:SS', mais vous permet d'assigner des valeurs
DATE en utilisant plusieurs formats de chaînes et nombres.
•TIMESTAMP : Un timestamp. L'intervalle de validité va de '1970-01-01 00:00:00' à
quelque part durant l'année 2037.
•TIME : MySQL affiche les valeurs TIME au format 'HH:MM:SS', mais vous permet
d'assigner des valeurs TIME en utilisant des nombres ou des chaînes.
•YEAR [(2|4)] : Une année, au format 2 ou 4 chiffres (par défaut, c'est 4 chiffres).
1.3.3 Les types de chaînes
Les types CHAR et VARCHAR sont similaires, mais diffèrent dans la manière dont ils sont
stockés et récupérés :
•CHAR : La longueur d'une colonne est fixée à la longueur que vous avez défini lors de la
création de la table. La longueur peut être n'importe quelle valeur entre 1 et 255. Quand une
valeur CHAR est enregistrée, elle est complété à droite avec des espaces jusqu'à atteindre la
valeur fixée. Quand une valeur de CHAR est lue, les espaces en trop sont retirés.
•VARCHAR : Les valeurs contenues dans les colonnes sont de tailles variables. Vous
pouvez déclarer une colonne VARCHAR pour que sa taille soit comprise entre 1 et 255,
exactement comme pour les colonnes CHAR. Par contre, contrairement à CHAR, les valeurs
de VARCHAR sont stockées en utilisant autant de caractères que nécessaire, plus un octet
pour mémoriser la longueur. Les valeurs ne sont pas complétées. Au contraire, les espaces
finaux sont supprimés avant stockage.
Si vous assignez une chaîne de caractères qui dépasse la capacité de la colonne CHAR ou
VARCHAR, celle ci est tronquée jusqu'à la taille maximale du champ.
1.4 Les index
Les bases de données sont souvent très volumineuses. Ainsi, une recherche d’information
dans une table peut prendre beaucoup de temps. L’index est l’outil qui permet de résoudre ce
problème.
L’index présente des avantages :
•Il accélère les recherches d’informations.
•Il est de taille très inférieure à celle de la table.
•Il peut servir à empêcher l’opérateur de créer des enregistrements dupliqués.
Mais il ne possède pas que des avantages, à chaque saisie, il faut le mettre à jour.
Les index jouent un rôle discret mais important dans la gestion des bases de données.
L’index rend les tris et les recherches d’informations plus rapides.

La décision de créer un index résulte de l’examen des avantages et inconvénients de cette
opération.
Malgré tout, on utilisera presque systématiquement un index.
2 LE MECANISME RELATIONNEL
2.1 Les données redondantes
Le gros problème dans la gestion des données est la saisie d’informations redondantes. A une
information longue, on attribue volontiers une référence ou un code. Cela permet d’éviter des
saisies répétitives et fastidieuses.
Les données maniées dans une entreprise sont structurées
2.2 Etude d ’ un exemple
2.2.1 Notion de relation
Chez un vendeur de matériaux, pour chaque produit, on enregistre : code, nom, prix unitaire,
code du fournisseur, état du stock, état minimal admissible (pour ne pas être en rupture de
stock), quantité minimale par commande…
Ces données sont rangées dans des tables.
Le gestionnaire du stock sait que le code du fournisseur relie la fiche "produit" à la table
"fournisseur".
Il faut donc construire une base de données relationnelle, c’est à dire capable de gérer les
relations.
Le schéma ci-dessus permet de constater que les informations relatives à un fournisseur ne
sont saisies qu’une fois, même si ce dernier fournit plusieurs produits.
C’est l’usage des codes qui permet ceci. Ici, on considère que chaque produit ne peut provenir
que d’un seul fournisseur.
En informatique, on parle de "relation un à plusieurs" ou relation "1-n".
2.2.2 La jonction
Considérons les bons de livraison. Pour chaque commande exécutée, il faut noter le
numéro de la commande, la date, le nom (ou le code) de l’entreprise, puis la liste des
produits (ou leurs codes) ainsi que les quantités livrées.
Un problème va se poser. Combien doit-on prévoir de colonnes pour le code du produit et
la quantité correspondante ?
Bons_livraisons

•La prévision de beaucoup de colonnes pour le code produit et la quantité va impliquer un
gaspillage de la mémoire.
•Inversement, si on en prévoit trop peu, il faudra éditer plusieurs bons pour une même
livraison.
Une nouvelle table appelée table de jonction va solutionner le problème. Cette table
va comporter 3 colonnes :
•Un code assurant le lien avec la table "Bons_livraisons"
•Codes des produits
•Quantités livrées
Un même bon de livraison peut mentionner plusieurs produits.
Un même produit peut apparaître dans de nombreux bons de livraison.
La création d’une table de jonction puisant ses codes dans deux autres tables
"Bons_livraisons" et "Produits" permet de résoudre notre problème.
On parle alors de relation "n-n" qui peut toujours être scindée en deux relations "1-n"
par création d’une table supplémentaire appelée "table de jonction".
2.3 Règles générales sur le schéma relationnel de la base
2.3.1 Introduction
La gestion de données courantes implique la création de plusieurs tables, reliées entre elles
via des codes.
Pour que le système fonctionne, il faut que les relations entre tables soient du type
"1-n".
Si on rencontre une relation de type "n-n", on peut toujours la scinder en deux
relations de type "1-n" par création d’une table de jonction supplémentaire.
2.3.2 Les relations "1-1"
Le nom d’une personne et son prénom sont liés de façon univoque. Nous dirons qu’ils sont
liés par une relation « un à un » ou "1-1". On les placera dans la même table.

REGLE 1: D’une manière générale, on placera dans la même table les données qui
sont en relation "1-1" entre elles.
2.3.3 Les relations "1-n"
Exemple : C’est le type de relation entre une personne et une entreprise.
•Un personne est généralement employée par une entreprise.
•Une entreprise emploie généralement plusieurs personnes.
C’est une relation « un à plusieurs » ou "1-n" entre la personne et l’entreprise.
Si on place le nom de l’entreprise dans la même table que le nom de la personne, il y aura
obligatoirement redondance. Il faut donc placer les personnes et les entreprises dans des
tables distinctes.
REGLE 2: Une relation "1-n" implique la création d’une nouvelle table.
REGLE 3: D’une façon générale, on recensera toutes les relations "1-n" existant
entre les données.
2.3.4 Les relations "n-n"
Exemple : Une personne par rapport à des organismes :
•Une personne peut être affiliée par plusieurs organismes.
•Un organisme gère plusieurs personnes.
On se retrouve face à une relation qui semble être "1-n" dans les deux sens, ce qui
signifie qu’il s’agit d’une relation « plusieurs à plusieurs » ou "n-n".
REGLE 4: Pour gérer une telle relation, il faut introduire une table de jonction avec
au minimum deux champs code afin d’obtenir deux relations de type "1-n".
2.3.5 Conclusion
Dans le processus de création d’une base de données, l’établissement du schéma
relationnel de la base de données représente l’étape fondamentale. Il est inutile d’aller
plus loin (donc de commencer à coder) tant que cette étape n’est pas parfaitement
maîtrisée.
 6
7
8
9
6
7
8
9
1
/
9
100%