SUPINFO E-Learning Course Template

Réseaux de neurones

Objectifs de ce module
Aborder une approche
radicalement différente des
autres modes de programmation.
Comprendre les principaux
concepts de simulation
informatique d'un neurone.
Maîtriser deux algorithmes
majeurs d' "apprentissage".
Evaluer les performances et les
limites d'un réseau neuronal.
Structurer et tester des "mini-
réseaux" (ex: OCR).
Les réseaux neuronaux

Plan du module
Notions de base
Le perceptron
Réseaux multicouches à rétro-propagation de l’erreur
Voici les parties que nous allons aborder:
Les réseaux neuronaux

Plan de la partie
Historique et développements
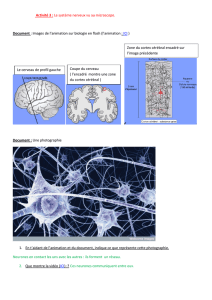
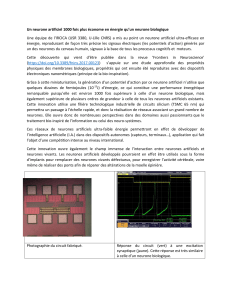
Modélisation du neurone
Types d’apprentissage
Voici les chapitres que nous allons aborder:
Notions de base

Approche algorithmique (programmation complète)
Création des « moteurs d’inférence » (programme qui
raisonne ; règles SI..ALORS.. ; système expert)
Approche connexionniste : le réseau s’organise par
apprentissage (pas de programmation)
Approches informatiques pour résoudre un problème :
Historique et développements
Notions de base
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
1
/
54
100%