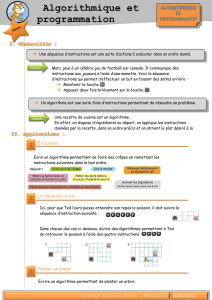
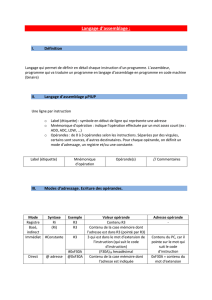
Les notes de cours

INF4170 – Architecture des ordinateurs
Notes de cours
1 Introduction
L’architecture des ordinateurs a évolué depuis les années 50. Nous avons été
témoins, au cours des dernières années, d’augmentations vertigineuses des
vitesses et capacités des ordinateurs. L’introduction de machines à jeux
d’instructions réduits formait la crête de la précédente vague de changements.
Le développement des ordinateurs personnels, construits autour des
microprocesseurs, fut le début de ce qui est maintenant considéré comme une
révolution informatique. Certaines des avancées ont été transparentes pour les
utilisateurs, d’autres servent d’arguments de marketing au point de s’intégrer à la
culture populaire.
Le développement du matériel n’a qu’un but, aller plus vite. Cet aspect, à lui seul,
ne détermine pas la performance d’un ordinateur. Le logiciel qui s’exécute sur un
ordinateur doit, idéalement, tirer partie d’une configuration matérielle dans le but
d’être optimal. Le matériel doit donc, en contrepartie, répondre de manière
souple et efficace, aux caractéristiques sémantiques des programmes, certaines
de ces caractéristiques sont intrinsèques aux langages de programmation et
systèmes d’exploitation. Les outils de programmation, les systèmes d’exploitation
ainsi que la configuration mémoire des ordinateurs ont également évolué
significativement depuis le début de l’informatique.
Le développement concurrent et parallèle, tantôt en tête, tantôt à la traîne, des
technologies de la programmation et du matériel, empêche de traiter
d’architecture des ordinateurs en négligeant l’aspect logiciel. Cette association
est particulièrement vraie au niveau des jeux d’instructions, et de l’organisation
des composantes. Le cours présentera donc une synthèse des solutions
matérielles aux besoins du logiciel. Il s’attardera aux problèmes, aux réponses
apportées, leurs implications, et dans une certaine mesure leur implantation.
Aujourd’hui, l’ordinateur est synonyme de numérisation de l’information et de
manipulation numérique de celle-ci. Il existe pourtant deux types d’ordinateurs,
l’analogique et le numérique. Les ordinateurs analogiques utilisent des
phénomènes physiques (circuits électriques ou hydrauliques, règles, poids) qui
simulent le modèle désiré, la lecture des tensions et pressions, positions et
courants, de ces systèmes permet la résolution des équations. Ces ordinateurs
(certains appelés intégrateurs ou différentiateurs) étaient d’usage courant jusqu’à
l’arrivée de l’ordinateur numérique, plus simple d’utilisation mais possédant
également leurs lots d’inconvénients. L’ordinateur numérique traite une
information encodée, binaire, grâce à une série de bascules. La conversion d’un

système analogique à un système numérique implique une phase
d’échantillonnage où seules certaines valeurs seront conservées. La densité et la
précision des échantillons établissent la qualité des données, elles influencent,
mais sans être l’unique facteur, la qualité des résultats obtenus. Le passage
inverse, du numérique à l’analogique est possible, l’approximation du système
analogique l’est d’autant plus que la précision et la densité des valeurs
numériques sont grandes (théorème de Shannon ou Nyquist). L’évolution de
l’utilisation des ordinateurs, pour les applications de gestion et scientifiques, s’est
accomplie en préservant la précision des données, des entiers pour les
inventaires et les comptes, des nombres à virgule flottante ou fixe pour des
valeurs décimales.
On attribue généralement à John von Neumann l’invention de l’ordinateur
numérique. Cette consécration est maintenant considérée comme surfaite. Il n’en
demeure pas moins un acteur, et témoin privilégié, des balbutiements des
ordinateurs de la première génération (1938-1953). Ces ordinateurs utilisaient
des lampes à vide et des relais électromécaniques. Les premières machines ne
stockaient pas de programmes en mémoire, elles devaient être programmées à
l’aide de séries d’interrupteurs. L’ENIAC (1946), le EDVAC (1950), le
EDSAC(1951) ainsi que la série des Mark I et Mark II effectuaient des calculs bit
à bit et étaient bâtis de milliers de composantes. La vitesse se mesurait en
microsecondes et la chaleur dissipée par chaque composante se mesurait en
watts plutôt qu’en milliwatts comme pour celles d’aujourd’hui. Le premier
ordinateur commercial, le UNIVAC fut introduit en 1951.
L’invention du transistor en 1948 permit une première miniaturisation des
ordinateurs, bien que cette transition ne fut complétée qu’au début des années
60. Les transistors remplacent avantageusement les lampes à vide, et relais
électromécanique, puisqu’ils occupent un espace restreint, consomment et
dissipent peu d’énergie tout en étant plus résilients. Cette seconde génération
(1952-1963) voit également l’émergence de nouveaux outils, l’assembleur
inventé par Wilkes (1951) permit de développer plus aisément les programmes,
le FORTRAN (1956) par IBM, le COBOL (1959) par l’armée américaine ainsi que
Algol en 1960, établirent les fondements de l’informatique et rendirent plus
accessible l’utilisation des ordinateurs. Les mémoires étaient bâties autour de
pièces magnétisées, les tores, dont l’orientation est modifiée par le passage d’un
courant électrique. Ces mémoires, complexes à construire, avaient un temps
d’accès (1 s), un mégaoctet valait 1 million de dollars. Les coûts d’opération des
ordinateurs étant prohibitifs, la rentabilité des systèmes passait par le
développement de techniques qui alliaient le travail du processeur et les
entrées/sorties. L’objectif de diminuer le temps pris par un programme pour
s’exécuter, se réalisa dans le cadre des systèmes d’exploitation, il demanda de
nouveaux supports par le matériel. L’introduction des disques à accès non-
séquentiels, en 1963 par IBM, révolutionna à son tour le monde de
l’informatique.

Les apprentissages de la décennie précédente, tant dans le domaine de la
technique que dans le domaine théorique, servirent de bases pour une nouvelle
génération de machines (1962-1975). La foi dans les capacités techniques, se
heurtant aux limites des connaissances, se traduisit par des machines
extrêmement complexes qui devaient résoudre tous les problèmes et se gérer
elles-mêmes. La stabilité appréhendée des architectures de cette génération
rendit possible la notion de familles d’ordinateurs, le principe sous-jacent étant
de fournir une version d’une architecture à l’échelle de la taille des problèmes à
résoudre et de l’organisation acquérant celle-ci.
La miniaturisation des composantes de cette génération se fit en utilisant des
circuits intégrés, inventés à la fin des années 50. Les premiers circuits intégrés
sont nommés circuits à petite échelle d'intégration (SSI small scale integrated).
La densité des composantes augmenta de manière fulgurante au cours des
années 60, en moyenne, elle doublait chaque année. Cette progression diminua
dans les années 70, elle quadrupla aux trois ans. Ces croissances de
performance se firent dans un contexte où le prix des composantes demeurait
constant, il s’en suivi d'une baisse vertigineuse du prix des éléments de base des
machines. La miniaturisation des composantes implique que la distance à
parcourir entre deux points est moindre, d’où une augmentation de vitesse mais
également une diminution de puissance et des besoins en refroidissement. Le
nombre moins élevé de connexions entre les éléments diminue le nombre de
pannes dues aux bris. La technologie des circuits associée à la fin de cette
période est appelée intégration moyenne (MSI medium scale integrated).
La quatrième génération d’ordinateurs (1972-1985) se développa autour d’un
nouveau niveau dans les circuits intégrés, la haute intégration (LSI large scale
integration), possédant un nombre de composantes de l’ordre de 1000 par
élément. La mémoire virtuelle, introduite par IBM au début des années 70, permit
d’augmenter l’espace adressable des programmes et par conséquent, la taille
des programmes. Notez qu’il existe des ordinateurs dont la taille de la mémoire
physique est supérieure à l’espace adressable. Le prix par bit de la mémoire
bâtie autour de circuits intégrés descendit sous celui du bit de la mémoire
magnétique vers 1974, permettant la mise au rancart des mémoires à tores.
L’introduction des microprocesseurs, Intel introduit le 4004 en 1971, et un des
premiers micro-ordinateurs dans la seconde moitié des années 70, ouvrirent la
voie à une révolution dans le monde de l’informatique. Parallèlement à ces
développements, plusieurs super ordinateurs furent introduits et le traitement
parallèle fit un bond. Certaines machines traitant simultanément plusieurs
données, en exécutant la même instruction sur des éléments de calcul différents,
alors que d’autres traitaient des données et des instructions différentes.
La complexité d’exécution des instructions, les faibles fréquences d’utilisation
des instructions ainsi que de certains modes d’adressage, provoqua dans la
seconde moitié des années 80 une suite d’études sur la possibilité de réduire la
complexité des instructions. L’hypothèse étant que des outils de développement

pouvaient être assez puissants pour générer des suites d’instructions simples à
exécuter sur des machines moins complexes. Les avancées de la miniaturisation
à très grande échelle (VLSI very large scale integrated), aidant à améliorer la
vitesse, et l’utilisation de pipelines, qui traitent en parallèle différentes instructions
rendues à des étapes intermédiaires différentes de leur cycle d’exécution,
permettent de diminuer le taux apparent de cycles nécessaires pour exécuter les
programmes, d’où de meilleures performances. Ces machines sont appelées
sont appelées RISC, pour Reduced Instruction Set Computers, par opposition au
CISC, Complex Instruction Set Computer. Le développement de ces machines
constitue la cinquième génération et nous y sommes toujours.
La contrainte ultime des machines est la lumière, cette contrainte existe sous
plusieurs formes, elle limite la vitesse de propagation du courant électrique (95%
de la vitesse de la lumière), elle limite également le procédé de fabrication des
circuits. Les circuits intégrés sont "gravés" à l’aide de la lumière. Ils sont
constitués de couches superposées d’isolant et de conducteur. On enduit un
morceau de silicium d’une couche d’oxyde de métal, puis d’une émulsion
photosensible, on recouvre le tout d’un masque laissant le tracé du circuit désiré
à découvert, on expose alors le masque à la lumière et l’émulsion est dégénérée,
on cuit l’émulsion qui sert à son tour de masque pour un traitement à l’acide qui
grave le métal, l’émulsion est par la suite lavée. La surface gravée est remplie
d'un conducteur.
La seconde couche est appliquée au-dessus de la première et ainsi de suite. On
atteint actuellement les limites de l’utilisation de la lumière parce que la largeur
des gravures approche la longueur d’onde de la lumière. On travaille à diminuer
la largeur mais cela occasionne plusieurs problèmes. Des techniques sont mises
au point pour utiliser des rayons X et des faisceaux d’électrons.
Les caractéristiques recherchées qui assurent, du moins jusqu’à aujourd’hui, le
succès d’un ordinateur sont : la généralité, soit la capacité d’exécuter toute une
gamme d’applications; l’efficacité, soit la capacité de générer une quantité de
résultats dans un certain laps de temps; et la malléabilité, soit la possibilité
d’avoir plusieurs configurations différentes (famille d’ordinateurs). La disponibilité
en qualité et quantité, l’ouverture du système et sa simplicité, les possibilités de
mises à jour et de remplacement de pièces sont autant de facteurs qui affectent
également le succès d’un ordinateur.

2 Ordinateur simple
2.1 Architecture, implantation et réalisation
L'homme utilise différents niveaux d'abstraction pour simplifier et décomposer,
un objet complexe en plusieurs couches. Dans le cas du matériel, on distingue
trois niveaux: l'architecture, l'implantation et la réalisation. L'architecture décrit
l'aspect présenté à l'utilisateur de la machine. Elle comprend l'assembleur, les
tailles et types de données, le nombre de registres et leurs noms, les modes
d'adressage, les contraintes de programmation. L'implantation décrit le choix des
composantes et leur organisation logique. Par exemple, l'utilisation de bus
parallèle ou série, la taille du cache, la position des unités fonctionnelles sur le
chip. La réalisation représente le matériel: filage, portes et circuits.
2.2 Modèle de von Newmann
Le modèle de von Newmann propose de stocker indifféremment les instructions
et les données d’un programme en mémoire de l’ordinateur. La généralité de la
mémoire étant gage de souplesse, chaque case possède sa propre adresse. La
distinction entre instruction et donnée est assurée par un compteur ordinal,
intégré à l’unité de traitement, passant séquentiellement d’une instruction à une
autre. L’unité de traitement contrôle l’accès à la mémoire et aux entrées/sorties.
Le lien unissant la mémoire et l'unité de traitement est un goulot d'étranglement
parce qu'il sert au transfert, tant dans un sens que dans l'autre, des adresses
(vers la mémoire) et des données et instructions (vers l'unité de traitement).
Facteur aggravant, les vitesses de ces composantes sont différentes (1 ordre de
grandeur), contraignant également la performance du système. Une variante de
ce modèle, appelé architecture de Harvard, sépare la mémoire de données des
instructions. Elle est fréquemment retrouvée dans les caches parce que le
comportement des références aux instructions est différent de celui des accès
aux données. Cette variante n'est cependant pas à l'abri de problèmes, que nous
verrons plus loin dans la section sur les mémoires.
2.3 Composantes et cycle des instructions
La section précédente décrit une machine simple. Ses principales composantes
sont la mémoire, les périphériques et l'unité centrale de traitement. Cette
dernière est constituée de l'unité arithmétique et logique (UAL) et de l'unité de
contrôle. Le liens physiques unissant les composantes sont appelés bus. Ils
peuvent être aussi bien utilisés pour contrôler les composantes que transmettre
des données et instructions.
Pour exécuter un programme, l’ordinateur traite une série d’instructions. Dans le
but d’exécuter une instruction, les étapes à suivre sont la localisation de
 6
7
8
9
10
11
12
13
14
15
16
17
18
6
7
8
9
10
11
12
13
14
15
16
17
18
1
/
18
100%