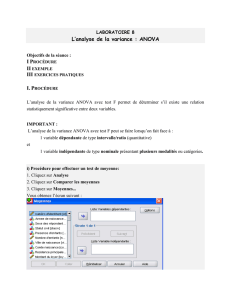
Exemple d`application d`une ANOVA à un critère

Exemple d’application d’une ANOVA à un critère, suivie d’une comparaison des moyennes multiples
Les données numériques se trouvent dans un fichier Excel « Exemple de test ANOVA.XLS ».
Les données utilisées proviennent de travaux pratiques qui devaient permettre d’étudier le développement de biofilms sur des
supports immergés dans l’eau. Cette manip a aussi permis de montrer que les feuilles mortes immergées dans l’eau perdent une
fraction non négligeable de leur masse par dissolution et a permis de tester l’hypothèse selon laquelle la fraction soluble des feuilles
diffère d’une espèce à l’autre.
Protocole : des feuilles jaunissantes (mais encore attachées à l’arbre) de plusieurs espèces (charme, pin, hêtre, bouleau et sureau)
étaient récoltées au début de novembre, séchées, pesées, immergées dans de l’eau pendant deux jours, puis à nouveau séchées et
pesées, ce qui permettait de mesurer leur perte de masse par infusion à froid. Cette perte de masse était convertie en pourcentage de
perte de masse.
Pour comparer les moyennes des pertes de masse des cinq espèces, le test le plus approprié est l’ANOVA à un critère, avec le
pourcentage de perte de masse comme variable dépendante et l’espèce d’arbre comme variable explicative. Toutefois ce test requiert
des données distribuées de manière normale. Comme il s’agissait de pourcentages ET que certains d’entre eux étaient inférieurs à
20%, il est certain que les distributions n’étaient pas normales, mais il est possible de les « normaliser » par une transformation
arcsinus des variables, c’est-à-dire que chaque proportion p (= pourcentage divisé par 100) est remplacée par p’ selon la
formule
pp arcsin'
. L’ANOVA est ensuite appliquée sur les données transformées.
Hypothèse nulle : les moyennes des pertes de masse sont les mêmes quelle que soit l’espèce, ce que l’on peut aussi écrire :
µCarpinus = µPinus = µFagus = µBetulus = µSambucus, où = µXxx est la moyenne de perte de masse de l’espèce Xxx.

Succession des calculs de l’analyse de variance (même numérotation sur la feuille Excel) :
1) On calcule la moyenne de chaque série et une moyenne sur l’ensemble des séries
2) On calcule la variation totale, sous forme de sommes des carrés des écarts à la moyenne (ou SCEM) (formule ci-dessous)
3) On calcule la variation intergroupe (formule ci-dessous)
4) On calcule la variation intragroupe (ou erreur) (formule ci-dessous)
Ces variations ont la propriété :
variation intergroupe + variation intragroupe = variation totale
5) On calcule les nombres de degrés de liberté (# ddl), avec la même propriété :
# ddl intergroupe + # ddl intragroupe = # ddl total
6) On calcule ensuite les carrés moyens intergroupe et intragroupe, c’est-à-dire les variations intergroupe et intragroupe relativisées
par leur nombre de degrés de liberté respectif.
Le rapport du carré moyen intergroupe sur le carré moyen intragroupe est comparé aux valeurs critiques de la table F de Snedecor
avec les nombres de degrés de liberté requis : (a) #ddl intergroupe et (b) #ddl intragroupe, ce qui fournit la valeur de p du test.
On utilise les formules suivantes :

Source de variation
SCEM
# ddl
Carré moyen
Test F
Totale
k
i
n
jij
iXX
1 1
2
)(
N – 1
Intergroupe
2
1)( XXn i
k
ii
k – 1
SCEM intergroupe /
# ddl intergroupe
Carré moyen inter /
carré moyen intra
Intragroupe
(= erreur)
k
i
n
j
i
ij
iXX
1 1
2
)(
N – k
SCEM intragroupe /
# ddl intragroupe
Où k le nombre de groupes
Xij est la donnée j dans le groupe expérimental i
i
X
est la moyenne arithmétique des individus du groupe i
X
est la moyenne arithmétique des individus des k groupes réunis
ni est l’effectif du groupe i
N est l’effectif des k groupes réunis
Application dans le fichier Excel :
Il comporte une feuille (« Données brutes feuilles ») avec les données acquises au laboratoire et les calculs jusqu’à la transformation
arcsinus des variables. Les moyennes et écarts types sont calculés sur les données non transformées, mais l’ANOVA sera appliquée
sur les données transformées (valeurs en rouge)
Il comporte une deuxième feuille (« ANOVA feuilles à la main ») qui donne tous les calculs : toutes les cellules surlignées en jaune
contiennent une formule.

Il comporte une troisième feuille (« ANOVA feuilles par Statistica ») qui montre comment les données doivent être mises en forme
pour l’analyse dans le logiciel Statistica® ainsi que les résultats (mêmes tests) obtenus avec ce logiciel.
Dans cet exemple, le résultat de l’ANOVA est que l’hypothèse nulle est rejetée avec p<0.001. Cela veut dire que l’on prend un risque
inférieur à 0.001 de se tromper en affirmant que les moyennes de pertes de masses ne sont pas égales. Cela ne veut pas dire pour
autant que chaque moyenne est différente des autres !
Pour le savoir, il faut comparer les moyennes deux à deux grâce à un test de comparaison des moyennes multiples. Il en existe une
demi douzaine ; celui qui est proposé ici est adapté à comparer des moyennes qui proviennent de séries avec des effectifs différents
(Tukey test with unequal sample sizes).
Succession des calculs du test de Tukey (même numérotation sur la feuille Excel) :
7) On classe les séries par ordre croissant des moyennes ; cette opération n’est pas vraiment indispensable mais elle facilitera les
calculs qui suivent
8) Pour chaque paire de moyennes, on calcule leur différence, leur erreur standard et enfin une valeur q qui sera comparée à la table
des valeurs critiques des distributions de q avec les nombres de degrés de liberté requis : (a) #ddl intragroupe de l’ANOVA et (b) le
nombre de séries, ce qui fournit la valeur de p du test. On utilise les formules suivantes :
ba
ab nn
s
SE 11
2
2
et

ab
ab
SE XX
q
Où SEab = erreur standard entre les séries a et b
s² = le carré moyen de la variation intragroupe (provient de l’ANOVA)
na et nb = les effectifs dans les séries a et b
Xa et Xb = les moyennes des séries a et b
Les résultats peuvent être présentés sous forme de matrice (voir 8’ dans la feuille Excel) ou rédigés de la manière suivante :
« l’analyse de la variance à un facteur appliqué sur les données transformées (arcsinus) a montré que les pertes de masses étaient très
significativement hétérogènes entre les cinq espèces étudiées ; le test de comparaison de moyennes multiples de Tukey pour des séries
inégales a ensuite permis de montrer que (a) la perte de masse est très significativement plus élevée pour le sureau (25.6 ± 4.0 %)
(moyenne ± écart type) que pour les quatre autres espèces, (b) la perte de masse est très significativement plus faible pour le pin (1.6 ±
0.7 %) que pour les quatre autres espèces et (c) qu’il n’y a pas de différence significative entre le charme (8.5 ± 2.4 %), le bouleau
(10.8 ± 3.6 %) et le hêtre (12.6 ± 2.7 %) »
[à noter qu’on est revenu aux données non transformées dans la conclusion], on peut aussi résumer ces résultats de la manière
suivante : µPinus < µCarpinus = µBetulus = µFagus < µSambucus.
1
/
5
100%