I.A de Kolda/LYCEE Bouna Kane/Année scolaire : 2020-2021
Leçon4.LASYNTHESEDESPROTEINES
Introduction
Les protéines sont des macromolécules complexes qui jouent un rôle fondamental dans la
structure et le fonctionnement cellulaire. Elles sont constituées d’acides aminés liés par des
liaisons peptidiques. L’information nécessaire à la synthèse des protéinesest contenue dans le
noyau, au niveau de l’ADN.
1. La structure des acides nucléiques (ADN et ARN)
1.1. Mise en évidence et Localisation de l’ADN et de l’ARN
a. Expérience : Test de Brachet
On dispose de trois lots de cellules ayant la même origine numéroté 1,2 et 3.
Les cellules du lot 1 sont traitées avec du vert de méthyle et de la pyronine. On
constate quelques instants plus tard que le noyau est coloré en vert et que le nucléole et le
cytoplasme sont colorés en rose.
Chez les cellules du lot 2 on fait d’abord agir une enzyme appelée désoxyribonucléase
(enzyme qui détruit l’ADN : ADNase) puis on les traite avec du vert de méthyl et de la
pyronine. On constate que le cytoplasme et le nucléole sont colorés en rose et pas de
coloration verte pour le noyau.
Chez les cellules du lot 3, on fait agir une enzyme appelée ribonucléase (enzyme qui
détruit l’ARN : ARNase) avant de les traités avec du vert du méthyl et de la pyronine. On
constate que le noyau est coloré en vert par contre le cytoplasme et le nucléole ne sont pas
colorés en rose.
b. Conclusion
L’ADN et l’ARN sont les deux acides nucléiques. L’ADNest localisé dans le noyau alors que
l’ARN dans le noyau et dans le cytoplasme.
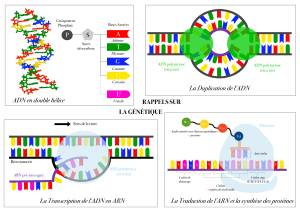
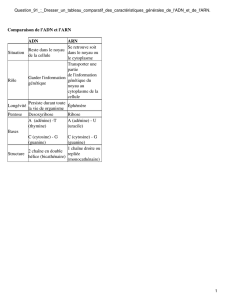
1.2. Composition et Structure de l’ADN et de l’ARN
a. Composition et Structure de l’ADN
Composition
L’hydrolyse enzymatique complète de l’ADN permet d’obtenir les constituants suivants :
4 bases azotées :adénine (A), Guanine(G),thymine (T) et cytosine (C)
L’adénineet la guanine sont les bases puriques ;la thymine et la cytosine sont les bases
pyrimidiques.
Un acide phosphorique (H3PO4)
Un sucre, le désoxyribose (sucre en C5 : C5H10O4)
Structure (En 1953, Watson et Crick)
La molécule d’ADN est formée de deux chaines (molécule bicaténaire)de
nucléotidesquis’enroulent l’une sur l’autre formant une double hélice.
Un nucléotide est constitué d’un sucre (désoxyribose), d’une base azotée (A ou T ou C ou G)
et d’une molécule d’acide phosphorique. Un nucléoside est constitué par l’association d’une
base azotée et d’un sucre.
Les bases azotées sont complémentaires car sur la molécule d’ADN l’adénine est toujours liée
à la thymine par deux liaisons d’hydrogène (liaison faible). La guanine est toujours liée à la
cytosine par trois liaisons d’hydrogène.

b. Composition et structure de l’ARN
Composition
L’ARN est constitué d’acide phosphorique, d’un sucre appelé ribose et de quatre bases
azotées : Adénine, Uracile, Cytosine et Guanine.
Structure
L’ARN est formé d’une seule chaine de nucléotides : on dit que c’est une molécule
monocaténaire. On distingue trois types d’ARN selon leur fonction : ARN de transfert
(ARNt), ARN messager (ARNm), et ARN ribosomial (ARNr).
Remarque : Du point de vu structurale, l’ADN a la forme d’une double hélice alors l’ARN a
la forme d’une hélice simple. Par sa composition, l’ARN diffère de celle de l’ADN sur deux
points : le ribose y remplace le désoxyribose, et l’uracile y substitue à la thymine.
2. Laréplicationdel’ADN
La réplication (ou duplication) de l’ADN est la synthèse de deux molécules d’ADN identiques
à partir d’une molécule d'ADN initiale. Elle se déroule avant chaque division cellulaire.
Au début de la réplication d’ADN l’hélicase,qui est une enzyme, entraine la rupture des
liaisons hydrogènes et l’écartement des 2 brins d’ADN matrice. Il se forme alors deux
fourches de réplication opposées qui constituent un œil de réplication. A partir de chaque brin
matrice, l’enzyme appelée ADN polymérase élabore une nouvelle chaine d’ADN en
incorporant les nucléotides libres aux brins matrices. A la fin, il se forme deux nouvelles
molécules d’ADN identiques.
Remarque : la réplication de l’ADN est semi-conservativecar les deux nouvelles molécules
formées possède chacune un brin issu de l’ADN initial et un brin nouvellement synthétisé.
NB : Le sens de fonctionnement de l’ADN polymérase est toujours 5’ 3’. Ceci implique que
l’un des brins aura une synthèse continue alors que l’autre sera discontinue
3. La synthèse des protéines
La synthèse des protéines se déroule en deux grandes étapes : la transcription et la
traduction.
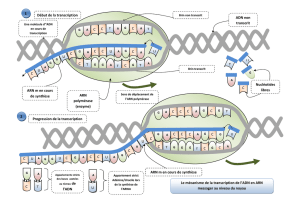
3.1. La transcription
L’ADN contenant l’information génétique ne peut sortir du noyau pour gagner le cytoplasme
où a lieu la synthèse. L’information génétique est acheminée au lieu de la synthèse par
l’ARNm.
La transcription est la synthèse de l’ARNm à partir d’une portion de brin d’ADN (le brin
transcrit). Elle débute à partir d’un site spécial de l’ADN appelé promoteur par où l’ARN
polymérase sépare les deux brins d’ADN. En suite cette enzyme catalyse la synthèse de
l’ARNm à partir des ribonucléotides libres du noyau. Cette synthèse s’arrête lorsque l’enzyme
rencontre une séquence de l’ADN appelée signal de terminaison. L’ARN se détache alors de
l’ADN et gagne le cytoplasme à travers les pores nucléaires.
NB : le brin non transcrit est le brin codant.
3.2. La traduction
La traduction est l’expression de la séquence des nucléotides l’ARNm en séquence d’acides
aminés ou protéine. Elle se fait selon la loi du code génétique.
a. Les caractéristiques du code génétique
On appellecode génétique le système de correspondance entre les bases azotées de l’ARNm
et les 20 acides aminés qui constituent les protéines.

Chaque séquence de trois bases azotées (triplet de base azotées) de l’ARNm est appelée un
codon. Chaque codon ne correspond qu’à un seul et un seul type d’acide aminé : on dit que le
code génétique est univoque. Exemple AUG=méthionine etc.
Par contre un acide aminé peut être codé par des codons différents : on dit que le code
génétique est redondant. Exemple sérine, alanine, etc.
Certains codons ne correspondent à aucun des vingt acides aminés : on les appelle les codons
stop ou codon non-sens. Ils sont au nombre de trois : UAA-UAG-UGA.
Ce code génétique est le même chez tous les êtres vivant : il est universel.
b. Déroulement de la traduction
Elle se déroule en trois phases successives: l’initiation, l’élongation et la terminaison.
L’initiation
Arrivé dans le cytoplasme, l’ARNm s’associe à la petite et grande sous-unité du ribosome. Au
même moment l’ARNt portant la méthionine occupe le site P du ribosome et se lie au premier
codon appelé codon initiateur. Ce codon est toujours l’AUG.
L’élongation
La traduction continue par l’arrivée d’un deuxième complexe ARNt-acide aminé qui occupe
le site A du ribosome. Son anticodon est complémentaire au 2ecodon de l’ARNm. Il se forme
une liaison peptidique entre le premier acide aminé et le second, on note également une
rupture de liaison entre le premier acide aminé et son ARNt. Le ribosome se déplace sur
l’ARNm libérant son site A où se fixera le troisième complexe ARNt-AA ainsi le processus se
répète avec l’ajout de nouveau AA et la protéine en formation s’allonge.
La terminaison
Elle se produit quand le site A du ribosome arrive au niveau d’un codon stop (UAA, UAG,
UGA) de l’ARNm qui ne correspond à aucun acide aminé. Il s’en suit un détachement des
sous-unités du ribosome et la libération de la protéine qui est séparée de la méthionine.
NB : l’ARNm peut être traduit simultanément par plusieurs ribosomes. Après la traduction les
ARNm sont détruits.
Conclusion
La synthèse des protéines est dirigée par l’ADN, support de l’information génétique. Elle se
fait en deux étapes essentielles : la transcription (ADN en ARNm) et la traduction (ARNm en
polypeptides). La maturation de ces polypeptides permet d’obtenir des protéines.Les protéines
jouent un rôle très important dans la vie cellulaire. Elles jouent un rôle structural (composition
de la membrane plasmique, des chromosomes…) mais aussi fonctionnelles (enzymes,
anticorps,…).
1
/
3
100%