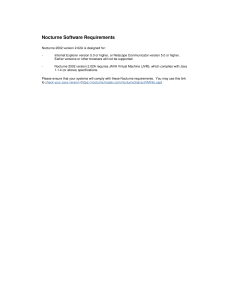
Online Banking App with Angular JS, REST, Cassandra
Telechargé par
abdelkhaleq elhaddad

St. Cloud State University
theRepository at St. Cloud State
4,-).!3).'1/*%#32)..&/1-!3)/.2241!.#% %0!13-%.3/&.&/1-!3)/.823%-2
Online Banking Application with Angular JS,
RESTful Web Services and Cassandra Database
Naga Sandeep Singh Bondili
Saint Cloud State University.2"/.$),)23#,/4$23!3%%$4
/,,/63()2!.$!$$)3)/.!,6/1+2!3 (;021%0/2)3/1823#,/4$23!3%%$4-2)! %3$2
:)23!11%$!0%1)2"1/4'(33/8/4&/1&1%%!.$/0%.!##%22"83(%%0!13-%.3/&.&/1-!3)/.823%-2!33(%%0/2)3/18!33,/4$3!3%3(!2"%%.
!##%03%$&/1).#,42)/.).4,-).!3).'1/*%#32)..&/1-!3)/.2241!.#%"8!.!43(/1)9%$!$-).)231!3/1/&3(%%0/2)3/18!33,/4$3!3%/1-/1%
).&/1-!3)/.0,%!2%#/.3!#3 126%7%,"!4-23#,/4$23!3%%$4
%#/--%.$%$)3!3)/.
/.$),)!'!!.$%%0).'(.,).%!.+).'00,)#!3)/.6)3(.'4,!1&4,%"%15)#%2!.$!22!.$1!!3!"!2%
Culminating Projects in Information Assurance
(;021%0/2)3/1823#,/4$23!3%%$4-2)! %3$2

Online Banking Application with Angular JS, RESTful Web Services and
Cassandra Database
by
Naga Sandeep Singh Bondili
A Starred Paper
Submitted to the Graduate Faculty of
St. Cloud State University
in Partial Fulfillment of the Requirements
for the Degree of
Master of Science
in Information Assurance
March 2017
Starred Paper Committee:
Dr. Dennis Guster
Dr. Susantha Herath
Dr. Kasi Balasubramaniam

2
Abstract
The purpose of this project is to show how new technologies help the banking and
financial industries to process and retrieve data for users. The primary goal of this project is to
demonstrate the new technologies Angular JS, RESTful Web Services, and the Cassandra
database which are faster than the other conventional software frameworks. This has been
achieved by creating two software applications; one is an online banking application with the
latest technologies and the other with traditional frameworks. After examining the time taken by
the techniques to render the web page to the user, and the availability and scalability of the
software, we will understand the need for the new technologies in the banking and financial
sectors. The application that is developed should help the users, guide them and should perform
user requested transactions with zero fault tolerance; it should give precise data without losing or
showing error data. It should also provide security to the transaction. Unauthorized transactions
should be prohibited from entering the server either from UI (User Interface) or from a mid-tier
connection. The proposed application uses the Cassandra database which has high scalability and
availability. It also uses Service Oriented Architecture (SOA) for better service and performance
of the application. In the UI we use Angular JS which is fast and can handle the REST
(Representational State Transfer) Application Programming Interface CRUD(Create, Read,
Update & Delete) operations.

3
Acknowledgement
The effective finish of this paper could not have been conceivable without the direction
of my professors Dr. Dennis Guster and Dr. Susantha Herath. I also would like to thank
Professor Kasi Balasubramanian for being part of the committee.

4
Table of Contents
Page
List of Table ................................................................................................................................ 6
List of Figures .............................................................................................................................. 7
Chapter
I. Introduction ...................................................................................................................... 9
Introduction ................................................................................................................ 9
Problem Statement ..................................................................................................... 9
Nature and Significance of the Problem .................................................................... 10
Objective of the Study ............................................................................................... 10
Study Questions/Hypotheses ..................................................................................... 10
Summary .................................................................................................................... 10
II. Background and Review of Literature ............................................................................. 11
Introduction ................................................................................................................ 11
Background Related to the Problem .......................................................................... 11
Current System Problems .......................................................................................... 11
Proposed System ........................................................................................................ 11
About the Technologies ............................................................................................. 12
Java ............................................................................................................................ 18
Spring Security........................................................................................................... 36
Angular JS .................................................................................................................. 39
Summary .................................................................................................................... 50
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
1
/
69
100%